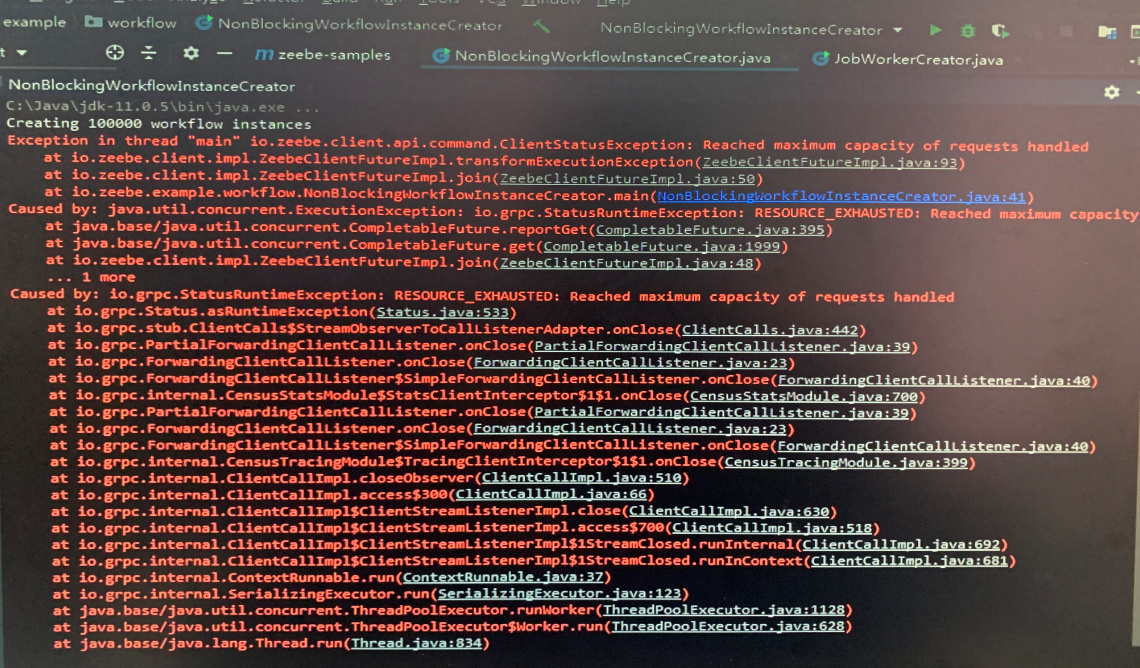
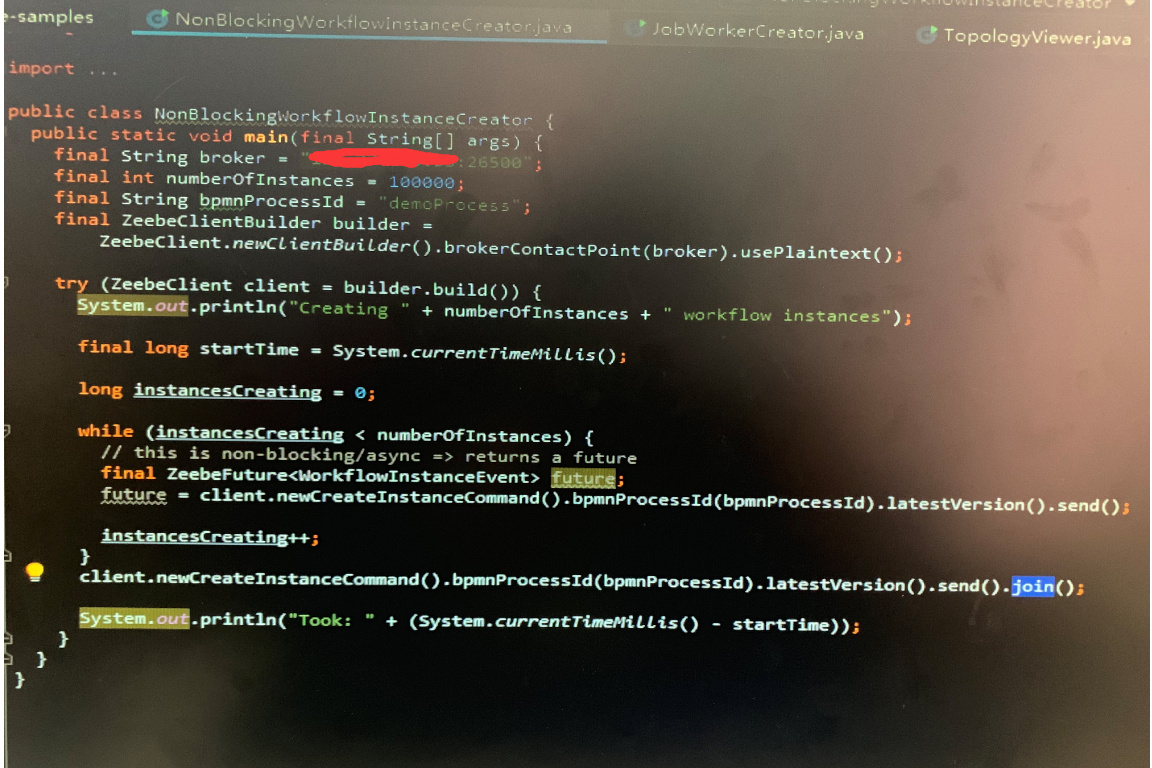
Running Zeebe 0.21.1 community and running into the exception above with these details:
Exception in thread “main” io.zeebe.client.api.command.ClientStatusException: Reached maximum capacity of requests handled
at io.zeebe.client.impl.ZeebeClientFutureImpl.transformExecutionException(ZeebeClientFutureImpl.java:93)
at io.zeebe.client.impl.ZeebeClientFutureImpl.join(ZeebeClientFutureImpl.java:50)
at SimpleHttpBasedProcessApp.main(SimpleHttpBasedProcessApp.java:48)
Caused by: java.util.concurrent.ExecutionException: io.grpc.StatusRuntimeException: RESOURCE_EXHAUSTED: Reached maximum capacity of requests handled
at java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357)
at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1895)
at io.zeebe.client.impl.ZeebeClientFutureImpl.join(ZeebeClientFutureImpl.java:48)
… 1 more
I am running a cluster comprising of 3 nodes using the docker/cluster sample. There are currently no workflow instances in flight. I get this error when attempting to run a single workflow and it occurs for every subsequent attempt in executing the same workflow.
If I run a single instance, I do not seem to run into this same problem. What could I be doing wrong?