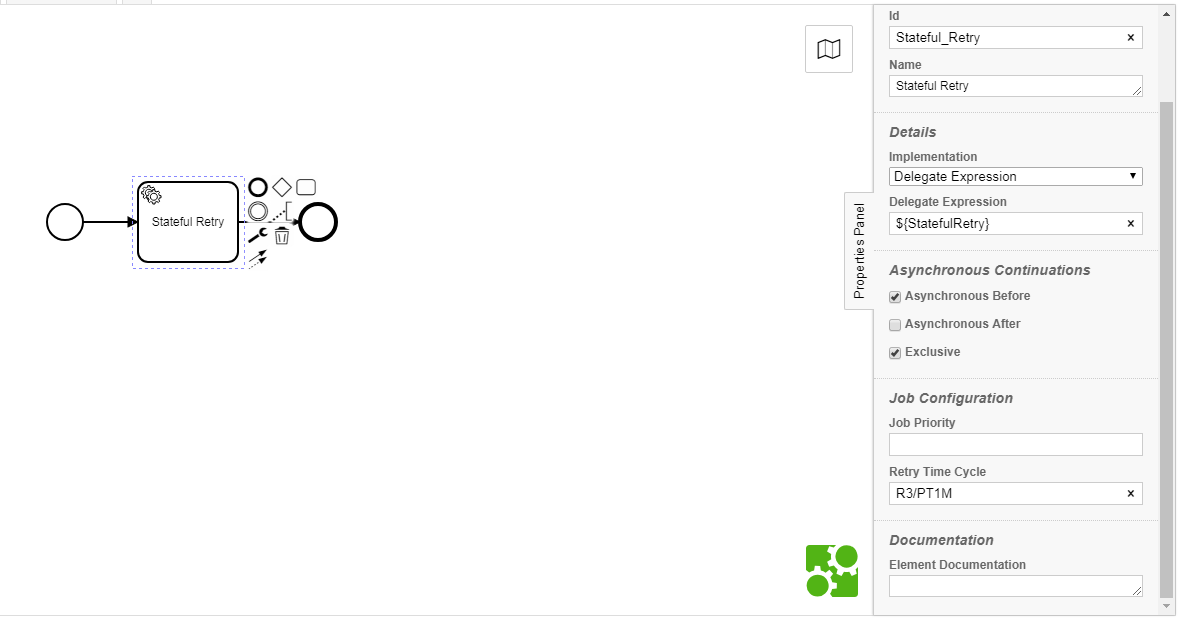
I want to implement a logic in Camunda to Retry a Service task for 3 times if that particular service task fails.For example I’m making an external API call in that Service task bean and I get exception in the response then I want perform the same service task again. I have used the Retry Time Cycle but when I’m explicitly throwing a BPMN error for a particular condition,then that task is not going into the Retry mode.
The error I’m getting is telling me to handle the error :- 2019-12-18 11:05:01.591 INFO 5908 — [aTaskExecutor-1] org.camunda.bpm.engine.bpmn.behavior : ENGINE-02001 Execution with id ‘Stateful_Retry’ throws an error event with errorCode ‘Test’, but no catching boundary event was defined. Execution is ended (none end event semantics).
@Component(“StatefulRetry”)
public class StatefulRetry implements JavaDelegate { @Override
public void execute(DelegateExecution execution) throws Exception {
System.out.println("Testing for RETRY");
throw new BpmnError("Test");
}
Is there a way to implement this logic using the Retry Time Cycle?
The retry feature is not related to the BPMN error event.
Retry’s happen when a technical error occurs and are caught by the engine. BPMN errors need to be caught by BPMN error events.
with the Retry Time Cycle you can actually define how many retries you want to allow and when the retries are supposed to happen.
However, rather than throwing a BPMN Error, try to throw a technical runtime exception instead. The job will then be retried with regards to the specification you made in the model. If you do not specify anything there, the defaults from the engine configuration will be used.
Imho, this is a design, not an implementation question. You should not model “simple” technical errors. So if your service is supposed to “just work”. do not handle exceptions your self, just let them be thrown. Your retry interval will kick in and after the retry count went zero, you will have an incident in the cockpit you should handle. Use this, if you are expecting the service to be up and functional, you only deal with it in rare exceptions. Example: Service delegate storing orders in a remote system … you can not do anything if the system is not available so you just retry and wait.
If you catch an exception and raise a bpmn error, this should mean that there is an alternative way to handle the error which is modeled in your BPMN. Example: Service that checks if an order can be fulfilled. If the service notices items out of stock, your process might want to handle this, by creating a user task that will check the order state manually or send out automated emails, …
TLDNR: if you throw a BPMN error, handle it in your process … otherwise, rely on exceptions and let the job executor/retry mechanism do the work.
Thanks for the replies guys. I’m clear now with the retries and the BPMN Error part. I manually throwed a Java Runtime Exception in the Service task bean and the process is getting retried 3 times for the intervals of time I’m defining in the Retry Time Cycle.