We have a workflow model that, sometimes, has running instances that get stuck on a service task. The service task is configured with Asynchronous Before. This seems to happen randomly. But, once an instance of the model gets stuck in this way, all subsequent instances of this model that are initiated also get stuck at the same service task. Here’s the really interesting behavior - if we make a new deployment of this model (with no changes to the model at all), we can then run instances of this new deployment successfully. However, the instances of the previous deployment that were previously stuck in the service task, remain stuck there.
Our environment is as follows:
Camunda 7.5.0
Running in the Apache Tomcat container
Using the standalone engine configuration
Using a mysql database running on Amazon RDS
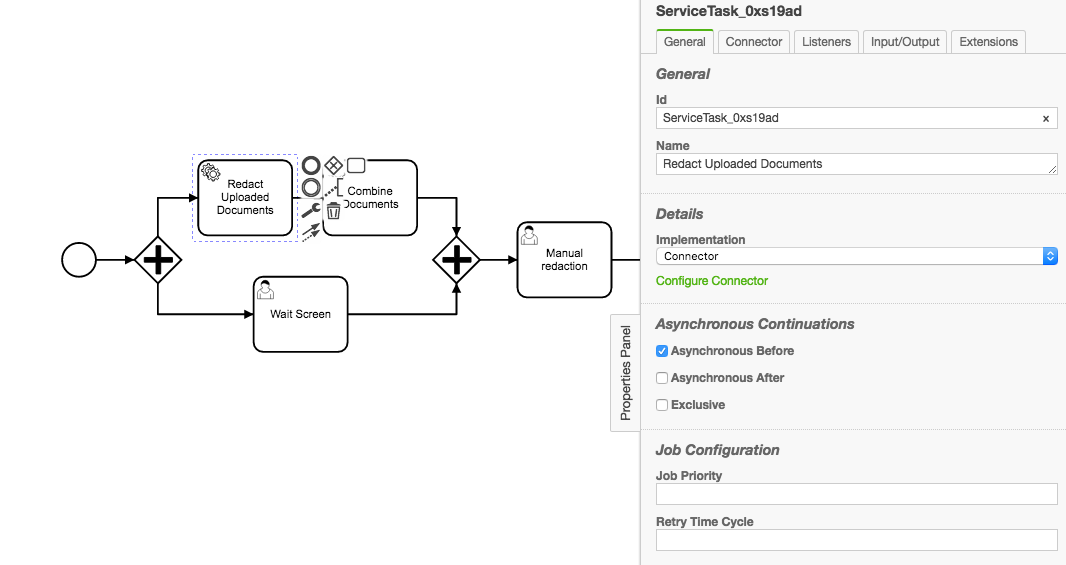
The relevant portion of the model is shown below. The service task named “Redact Uploaded Documents” is the task that gets stuck. This task is an http-connector that issues a POST to one of our own application endpoints. We have extensive logging in our application and the logging indicates that our endpoint is not getting called. We have also examined the catalina log and find no errors there. So it appears that this service task is not getting executed at all.
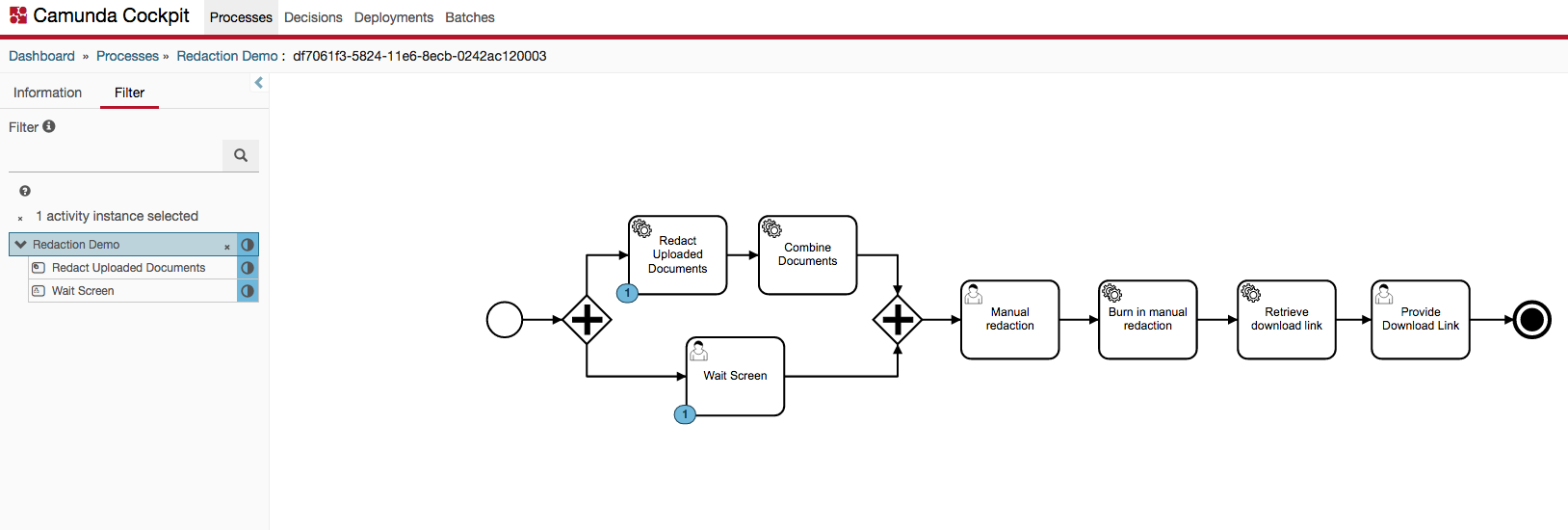
A Cockpit screenshot is show below showing an instance stuck in this state:
I have tried to track down this problem by executing various REST API queries to check on the activities, jobs, etc. Those queries are shown below:
engine-rest/execution?processInstanceId=df7061f3-5824-11e6-8ecb-0242ac120003
[
{
"id": "df7061f3-5824-11e6-8ecb-0242ac120003",
"processInstanceId": "df7061f3-5824-11e6-8ecb-0242ac120003",
"ended": false,
"tenantId": null
},
{
"id": "df70890c-5824-11e6-8ecb-0242ac120003",
"processInstanceId": "df7061f3-5824-11e6-8ecb-0242ac120003",
"ended": false,
"tenantId": null
},
{
"id": "df70890d-5824-11e6-8ecb-0242ac120003",
"processInstanceId": "df7061f3-5824-11e6-8ecb-0242ac120003",
"ended": false,
"tenantId": null
},
{
"id": "df70890e-5824-11e6-8ecb-0242ac120003",
"processInstanceId": "df7061f3-5824-11e6-8ecb-0242ac120003",
"ended": false,
"tenantId": null
}
]
engine-rest/process-instance/df7061f3-5824-11e6-8ecb-0242ac120003/activity-instances
{
"id": "df7061f3-5824-11e6-8ecb-0242ac120003",
"parentActivityInstanceId": null,
"activityId": "RedactionDemo:39:4e60cb5c-52a0-11e6-bd44-0242ac120003",
"activityType": "processDefinition",
"processInstanceId": "df7061f3-5824-11e6-8ecb-0242ac120003",
"processDefinitionId": "RedactionDemo:39:4e60cb5c-52a0-11e6-bd44-0242ac120003",
"childActivityInstances": [
{
"id": "UserTask_0fg7rbr:df70b01f-5824-11e6-8ecb-0242ac120003",
"parentActivityInstanceId": "df7061f3-5824-11e6-8ecb-0242ac120003",
"activityId": "UserTask_0fg7rbr",
"activityType": "userTask",
"processInstanceId": "df7061f3-5824-11e6-8ecb-0242ac120003",
"processDefinitionId": "RedactionDemo:39:4e60cb5c-52a0-11e6-bd44-0242ac120003",
"childActivityInstances": [],
"childTransitionInstances": [],
"executionIds": [
"df70890e-5824-11e6-8ecb-0242ac120003"
],
"activityName": "Wait Screen",
"name": "Wait Screen"
}
],
"childTransitionInstances": [
{
"id": "df70890d-5824-11e6-8ecb-0242ac120003",
"parentActivityInstanceId": "df7061f3-5824-11e6-8ecb-0242ac120003",
"processInstanceId": "df7061f3-5824-11e6-8ecb-0242ac120003",
"processDefinitionId": "RedactionDemo:39:4e60cb5c-52a0-11e6-bd44-0242ac120003",
"activityId": "ServiceTask_0xs19ad",
"activityName": "Redact Uploaded Documents",
"activityType": "serviceTask",
"executionId": "df70890d-5824-11e6-8ecb-0242ac120003",
"targetActivityId": "ServiceTask_0xs19ad"
}
],
"executionIds": [
"df7061f3-5824-11e6-8ecb-0242ac120003",
"df70890c-5824-11e6-8ecb-0242ac120003"
],
"activityName": "Redaction Demo",
"name": "Redaction Demo"
}
engine-rest/process-instance/df7061f3-5824-11e6-8ecb-0242ac120003
{
"links": [],
"id": "df7061f3-5824-11e6-8ecb-0242ac120003",
"definitionId": "RedactionDemo:39:4e60cb5c-52a0-11e6-bd44-0242ac120003",
"businessKey": null,
"caseInstanceId": null,
"ended": false,
"suspended": false,
"tenantId": null
}
engine-rest/job-definition?processDefinitionId=RedactionDemo:39:4e60cb5c-52a0-11e6-bd44-0242ac120003
[
{
"id": "4e60cb5d-52a0-11e6-bd44-0242ac120003",
"processDefinitionId": "RedactionDemo:39:4e60cb5c-52a0-11e6-bd44-0242ac120003",
"processDefinitionKey": "RedactionDemo",
"jobType": "async-continuation",
"jobConfiguration": "async-before",
"activityId": "ServiceTask_0xs19ad",
"suspended": false,
"overridingJobPriority": null,
"tenantId": null
}
]
engine-rest/job?processInstanceId=df7061f3-5824-11e6-8ecb-0242ac120003
[
{
"id": "df7ac245-5824-11e6-8ecb-0242ac120003",
"jobDefinitionId": "4e60cb5d-52a0-11e6-bd44-0242ac120003",
"processInstanceId": "df7061f3-5824-11e6-8ecb-0242ac120003",
"processDefinitionId": "RedactionDemo:39:4e60cb5c-52a0-11e6-bd44-0242ac120003",
"processDefinitionKey": "RedactionDemo",
"executionId": "df70890d-5824-11e6-8ecb-0242ac120003",
"exceptionMessage": null,
"retries": 3,
"dueDate": null,
"suspended": false,
"priority": 0,
"tenantId": null
}
]
engine-rest/execution/df70890d-5824-11e6-8ecb-0242ac120003
{
"id": "df70890d-5824-11e6-8ecb-0242ac120003",
"processInstanceId": "df7061f3-5824-11e6-8ecb-0242ac120003",
"ended": false,
"tenantId": null
}
Here is the ACT_RU_JOB db table row for the relevant job:
ID_, REV_, TYPE_, LOCK_EXP_TIME_, LOCK_OWNER_, EXCLUSIVE_, EXECUTION_ID_, PROCESS_INSTANCE_ID_, PROCESS_DEF_ID_, PROCESS_DEF_KEY_, RETRIES_, EXCEPTION_STACK_ID_, EXCEPTION_MSG_, DUEDATE_, REPEAT_, HANDLER_TYPE_, HANDLER_CFG_, DEPLOYMENT_ID_, SUSPENSION_STATE_, JOB_DEF_ID_, PRIORITY_, SEQUENCE_COUNTER_, TENANT_ID_
'df7ac245-5824-11e6-8ecb-0242ac120003', '1', 'message', NULL, NULL, '0', 'df70890d-5824-11e6-8ecb-0242ac120003', 'df7061f3-5824-11e6-8ecb-0242ac120003', 'RedactionDemo:39:4e60cb5c-52a0-11e6-bd44-0242ac120003', 'RedactionDemo', '3', NULL, NULL, NULL, NULL, 'async-continuation', 'transition-create-scope', '4e54483a-52a0-11e6-bd44-0242ac120003', '1', '4e60cb5d-52a0-11e6-bd44-0242ac120003', '0', '1', NULL
Here is the ACT_HI_JOB_LOG entry:
ID_, TIMESTAMP_, JOB_ID_, JOB_DUEDATE_, JOB_RETRIES_, JOB_PRIORITY_, JOB_EXCEPTION_MSG_, JOB_EXCEPTION_STACK_ID_, JOB_STATE_, JOB_DEF_ID_, JOB_DEF_TYPE_, JOB_DEF_CONFIGURATION_, ACT_ID_, EXECUTION_ID_, PROCESS_INSTANCE_ID_, PROCESS_DEF_ID_, PROCESS_DEF_KEY_, DEPLOYMENT_ID_, SEQUENCE_COUNTER_, TENANT_ID_
'df7b3776-5824-11e6-8ecb-0242ac120003', '2016-08-01 20:16:47', 'df7ac245-5824-11e6-8ecb-0242ac120003', NULL, '3', '0', NULL, NULL, '0', '4e60cb5d-52a0-11e6-bd44-0242ac120003', 'async-continuation', 'async-before', 'ServiceTask_0xs19ad', 'df70890d-5824-11e6-8ecb-0242ac120003', 'df7061f3-5824-11e6-8ecb-0242ac120003', 'RedactionDemo:39:4e60cb5c-52a0-11e6-bd44-0242ac120003', 'RedactionDemo', '4e54483a-52a0-11e6-bd44-0242ac120003', '1', NULL
I don’t see anything unusual in any of the data posted above. But may someone can see something that would explain why this process-instance is stuck in the service task.
At this point, we are stuck and have no clue as to what could be causing this. Any help would be greatly appreciated. If additional data is required, please let me know.