Hello my friend!
The signal event works correctly, but maybe it’s not the best solution… but I don’t quite understand the idea…
Let me understand better… you will have several instances running in the Webservice Call service task… and when one of the instances “Exits” from this service task, you want to trigger the event so that all instances exit their execution and start her again?
The Signal event works like this: It has a global scope in your application, that is, all instances that are locally waiting for the signal… when they receive this signal, they will follow the flow defined by this event.
Notice this image below:
I have 4 instances running in the “Webservice Call”… however when one of them finishes execution, and reaches the Signal End Event, the other 3 instances that were running are thrown out of this task through the Signal Boundary Event.
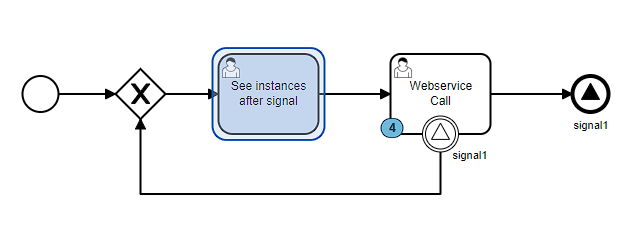
Here you can see that one instance finished execution via the happy path, and triggered the signal end event, and the other 3 instances returned to the previous step, as they all received the signal event.
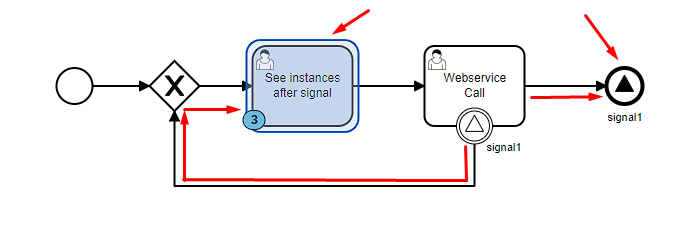
If the idea is this… when the first instance finishes, it means that the others that are executing the task, or waiting for retries… will be triggered to restart the process and call the service again, “skipping” the step of retry.
However, this seems like a bad solution to me… because imagine that, in a perfect scenario where everything is running well… imagine you have 100 instances in the WebService Call, and it’s just taking a while to execute, but it hasn’t triggered any retry , because there was no error… when any instance of yours finishes the process, it will trigger the event and make all your instances restart the process from scratch again without need… entering a loop and probably crashing your application in a short time.
Or maybe I didn’t understand the idea hehehehe…
But I remain at your disposal and hope I helped.
William Robert Alves
