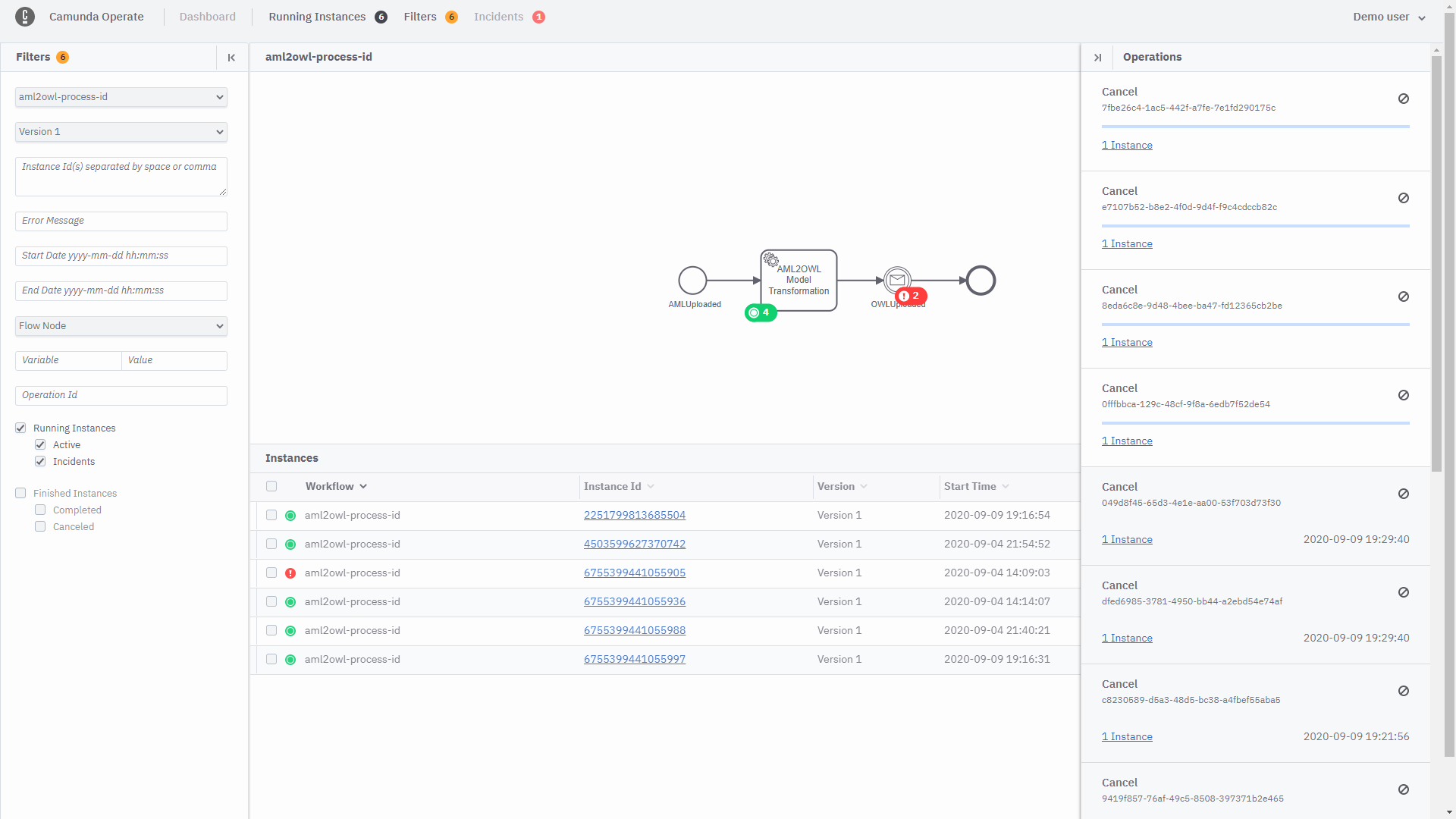
Click the Cancel instance button in Operate, and the rotating circle has been displayed for several hours.
I tried cancel from zbctl, but the situation has not improved, ActivateJobs can still see all the jobs.
Using Kubenetes 1.18.0, helm: zeebe-full, default settings.
Docker image camunda/zeebe:0.23.4
If the jobs are still activating, then the process has not been cancelled.
There are two channels for Operate: one is the Read channel, which is a connection to ElasticSearch. It sounds like this is working fine.
The other is the Write (Command) channel. For this, Operate needs to access the gRPC API on the Zeebe cluster gateway. If this connection is not working, you would see this behaviour.
Before this, I also encountered this problem, so I used helm to completely reinstall the zeebe server, but after that I still could not delete any workflow instances.
The gprc gateway is working well, I can create workflow instance, publish message, and more.
Oh, I see a long error log when I type kubectl logs zeebe-zeebe-0:
Caused by: java.net.SocketTimeoutException: 30,000 milliseconds timeout on connection http-outgoing-31 [ACTIVE]
at org.elasticsearch.client.RestClient$SyncResponseListener.get(RestClient.java:944) ~[elasticsearch-rest-client-6.8.9.jar:6.8.9]
at org.elasticsearch.client.RestClient.performRequest(RestClient.java:233) ~[elasticsearch-rest-client-6.8.9.jar:6.8.9]
at org.elasticsearch.client.RestHighLevelClient.internalPerformRequest(RestHighLevelClient.java:1764) ~[elasticsearch-rest-high-level-client-6.8.9.jar:6.8.9]
at org.elasticsearch.client.RestHighLevelClient.performRequest(RestHighLevelClient.java:1734) ~[elasticsearch-rest-high-level-client-6.8.9.jar:6.8.9]
at org.elasticsearch.client.RestHighLevelClient.performRequestAndParseEntity(RestHighLevelClient.java:1696) ~[elasticsearch-rest-high-level-client-6.8.9.jar:6.8.9]
at org.elasticsearch.client.RestHighLevelClient.bulk(RestHighLevelClient.java:472) ~[elasticsearch-rest-high-level-client-6.8.9.jar:6.8.9]
at io.zeebe.exporter.ElasticsearchClient.exportBulk(ElasticsearchClient.java:148) ~[zeebe-elasticsearch-exporter-0.23.4.jar:0.23.4]
at io.zeebe.exporter.ElasticsearchClient.flush(ElasticsearchClient.java:131) ~[zeebe-elasticsearch-exporter-0.23.4.jar:0.23.4]
... 8 more
and for kubectl logs zeebe-operate-66f9f5fdb-qvmsz
org.camunda.operate.exceptions.PersistenceException: org.camunda.operate.exceptions.PersistenceException: Error when processing bulk request against Elasticsearch: 30,000 milliseconds timeout on connection http-outgoing-119 [ACTIVE]
at org.camunda.operate.zeebeimport.AbstractImportBatchProcessor.performImport(AbstractImportBatchProcessor.java:34) ~[camunda-operate-importer-common-0.23.0.jar!/:?]
at org.camunda.operate.zeebeimport.ImportJob.processOneIndexBatch(ImportJob.java:116) ~[camunda-operate-importer-0.23.0.jar!/:?]
at org.camunda.operate.zeebeimport.ImportJob.call(ImportJob.java:80) ~[camunda-operate-importer-0.23.0.jar!/:?]
at org.camunda.operate.zeebeimport.RecordsReader.lambda$scheduleImport$1(RecordsReader.java:219) ~[camunda-operate-importer-0.23.0.jar!/:?]
at java.util.concurrent.FutureTask.run(Unknown Source) [?:?]
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source) [?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source) [?:?]
at java.lang.Thread.run(Unknown Source) [?:?]
Hello, I have the same behavior but in version 8.0.0 of zeebe on a kubernetes 1.19.4 cluster, every time I have more instances that cannot be cancelled. I need help please. Thank you