I am working on a few different usage patterns for how “Status Updates” come in from a external system as a message.
The two main patterns that I have been exploring is:
-
single process that has a “event loop” that captures a generic message from the external system, parses the message and generates a “Status Update”.
-
A overall process that manages the main flow, but a second stand-alone process that have a message start event that catches the message and processes.
The main difference in my mind is: "whether to have a single process with the “event loop” or have the “stand-alone” processes.
Would love community’s thoughts and opinions.
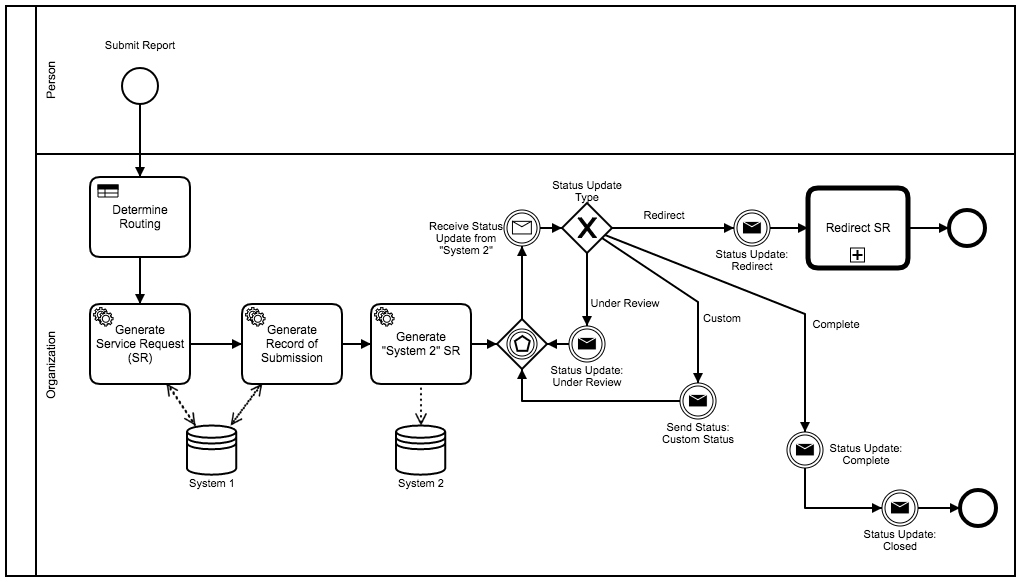
here is a example of the Event Loop scenario:
Ignore the semi-improper use of the lanes  Mainly being used at this point for framing the conversation.
Mainly being used at this point for framing the conversation.
edit: also note in the event loop example, the Event Gateway is used to help keep the diagram a little more clean and easier to read + a variation on this pattern is to have different Catch message events rather than the single Catch and the Exclusive Gateway.
Edit: My initial thoughts for the Event Loop pattern is that is could create a scenario where System 2 sends the message but the process is not waiting to catch it? @camunda can you provide any info about how the “queue” of messages works? If a process looks to catch the message after the message was already sent from System 2, will the process still catch the message? (aka: System 2 generates Message before Process reaches Catch event).
Hey @StephenOTT,
Regarding your last paragraph, that won’t work. If a process instance is not yet waiting for a message when you attempt to correlate it, the message is either ignored or an exception is thrown, depending on which API method you use.
Perhaps a message queue in front of the process engine could be used to work around this limitation, i.e. by putting messages into the message queue and repeatedly attempt correlation until it succeeds, probably with a backoff time interval. Not a nice solution but it might work.
Cheers,
Thorben
I figured as much! This is why i was thinking about the Second scenario. There is not “real” benefit of the Event Loop scenario over the stand-alone processes.
@thorben, Camunda does not have any implementations of repeating Message correlation attempts on failure?
Correct. Only when the message is correlated from within another process instance, the job executor’s retry mechanism would give you something like that.
@thorben Is there any design reasons for messages sent into camunda from the API, not be to processed through the/a job executor? (just curious)
Given the lack of “retry” on correlation, I think the “stand-alone” pattern would make more sense, and would not have to deal with any of the problems listed above.
Hi Stephen,
There is no hard reason for not using the job executor. The reasons for the way it is now are that this behavior is consistent with almost all other APIs where retry on failure is to be handled by the caller (e.g. on task completion). In addition, having this handled by the job executor would be more complex than just creating a job (e.g. for how long should a message be kept?). And lastly, a job-based solution is not very efficient since it means constant polling which may block other jobs.
A proper solution in the process engine would probably be the other way round: If a message is received and cannot be immediately correlated, put it in a table. If a process instance reaches a message event, look into the message table and continue or wait depending on whether a message is found.
Cheers,
Thorben
1 Like
Hi Stephen,
Would a non-interrupting event driven sub-process meet your requirement? In the pst Ive built event driven FSMs using scopes and event sub processes…
regards
Rob
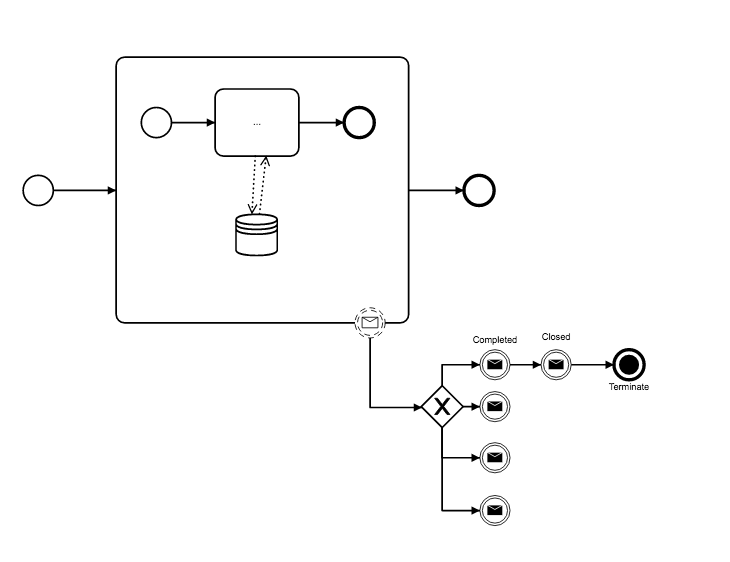
@Webcyberrob how would this deal with the loop requirement? Essentially any number of messages would come in at any time until a specific message is received that ends the process.
In the BPMN above it really should a terminate for the two end events so no stray tokens keep the process open.
Edit: @Webcyberrob where you thinking something like this?
just threw it together. not clear if it would actually function well in the engine.
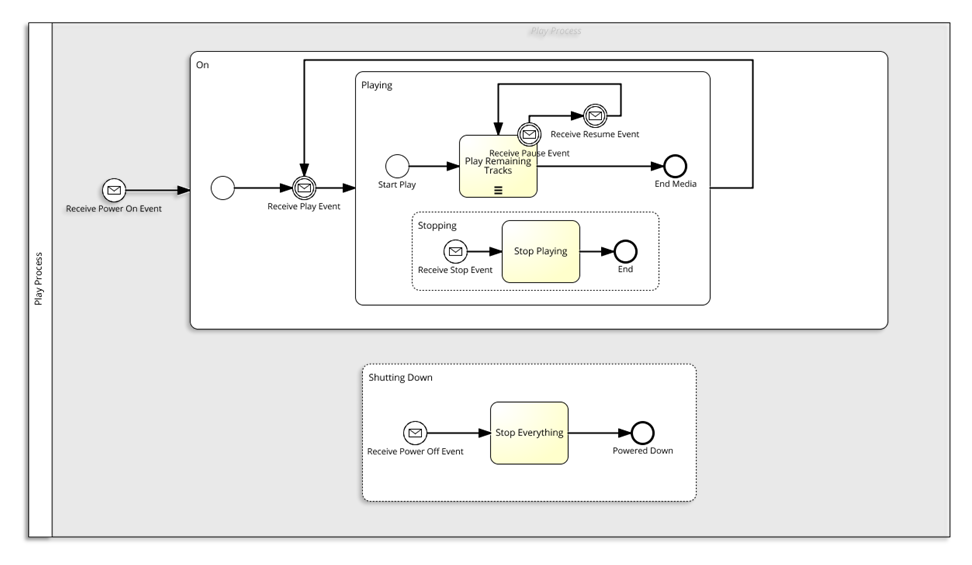
Hi Stephen,
Heres a slightly contrived example of what I mean. Rather than an event dispatch loop, can you represent the concept as an event driven FSM? In this case Ive modeled a player experience as an event driven FSM with interrupting event driven sub-processes…
regards
Rob