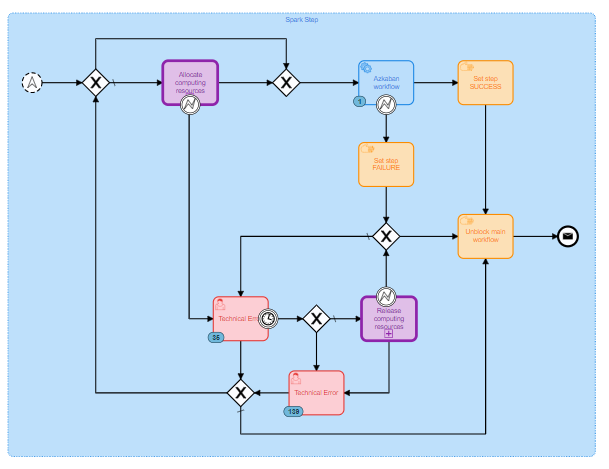
I’m using boundary timer event in my workflows plugged on user tasks : idea is that, either user is doing some action on the workflow within a given time frame, either the timer boundary event fire to do something automatic.
My timer definition type is duration and my timer definition is PT1M. Below is a screenshot of my workflow.
What is happening is that for the first 138 instances everything went fine, in the sense that I ended up in the user task, have done nothing manually and the timer fired correctly. But since 3 days now, each time I end up in my user task, the timer is no more firing, and the workflows (35 of them now) stay stuck in the same user task.
I’m not finding a lot of material about timer boundary event issues, just that you shouldn’t use less than a minute for the duration and that the duration corresponds to the minimum amount of time while the timer won’t fire and not to the exact duration of the timer. Also it seems possible to set globally a maximum amount of time for the timer when embedding camunda engine in a custom webapp :
No errors in the logs. What is strange, is that the timers worked fine for 1 week and suddently they stopped firing. Is it possible that the number of instance of the workflow can affect the timer event ? I experienced the same on another workflow running instances on another camunda engine. Everything was fine up to roughly 100-130 instances and then the timers stopped firing again.
The job executor settings are most likely to affect your timer. It’s the part of the engine that picks up the jobs and runs them. Luckily enough @thorben wrote a great blog post on friday about the job executor and that could help you understand what’s going on.
Following the @thorben blog post I was able to see that my timer job was not picked up by the job acquisition thread. I also see that the where clause of the query generated by the job acquisition thread, does not include the deployment id of the process instance whose timer never fire. Since I’m not using shared process engine with process applications, I tried to deactivate the process engine configuration property jobExecutorDeploymentAware. And it seems to solve the problem ! Not sure why though ? Also, I’m running camunda in a Kubernetes pod and it seems that when the pod is killed and recreated, all timers from process instances created from deployments prior to the restart do not fire anymore. Does it mean that, when restarting a pod, Camunda job executor does not consider, that deployments made before pod restart, belong to the node anymore and so excludes them from the query to acquire jobs ?
.