I’ve seen a few post before about this but since it’s still happening, I write this again.
The timer start events works fine… for like 3 days and then they just simple stop triggering. The same thing happens with timer intermediate events. specially with they are set to be triggered at specific times.
I have an standalone camunda set up in a Kubernetes environment. If I deploy the processes again, the start working again, for 3 days.
I read around that it might be resources so I increased the pod resources and the number of pods. So now I have 4 pods up to 2GB RAM capacity.
I don’t know what else to do.
I checked the jobExecution and it’s active and seems to be working but for only a very limited period of time. I’m desperate here.
Have you noticed if the timers always stop working after the same amount of time has passed (you say like 3 days - but is it always 3 days or does that change?
Usually 3 days every single time. One time it lasted 5 days and another time 4 days. But 3 days almost all the time no matter the hour and no matter the processes.
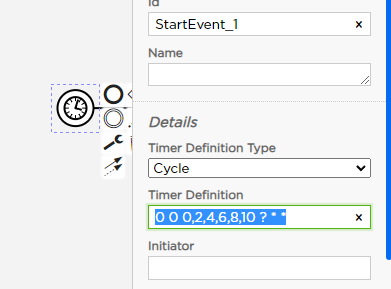
They all have that king of cron expression though, Might that be the problem?
The fact they do not stop at the same time confirms my suspicion. I think this could be related to the job executor and deployment awareness. When this is running inside a Kubernetes cluster it means that pods can go down and be created again and that might impact existing timers. What kind of setup do you have (Java process applications / process deployments with external task) ?