We are following the official AI Email Support Agent blueprint from the camunda-8-tutorials repository. Our goal is to run the full end-to-end flow — email received → fetch past conversations → AI Agent (LLM) → reply via email — in a self-managed environment without AWS Bedrock, since Titan Embeddings is unavailable in our AWS region (eu-north-1) on the free tier.
We are using CONNECTORS_SECRET_ANTHROPIC_API_KEY (Claude Sonnet) for the AI Agent step, which works correctly when the process reaches it. The blocker is the Embeddings Vector Database step that precedes it.
Issue 1 — Stuck process instances returning NOT_FOUND on cancellation
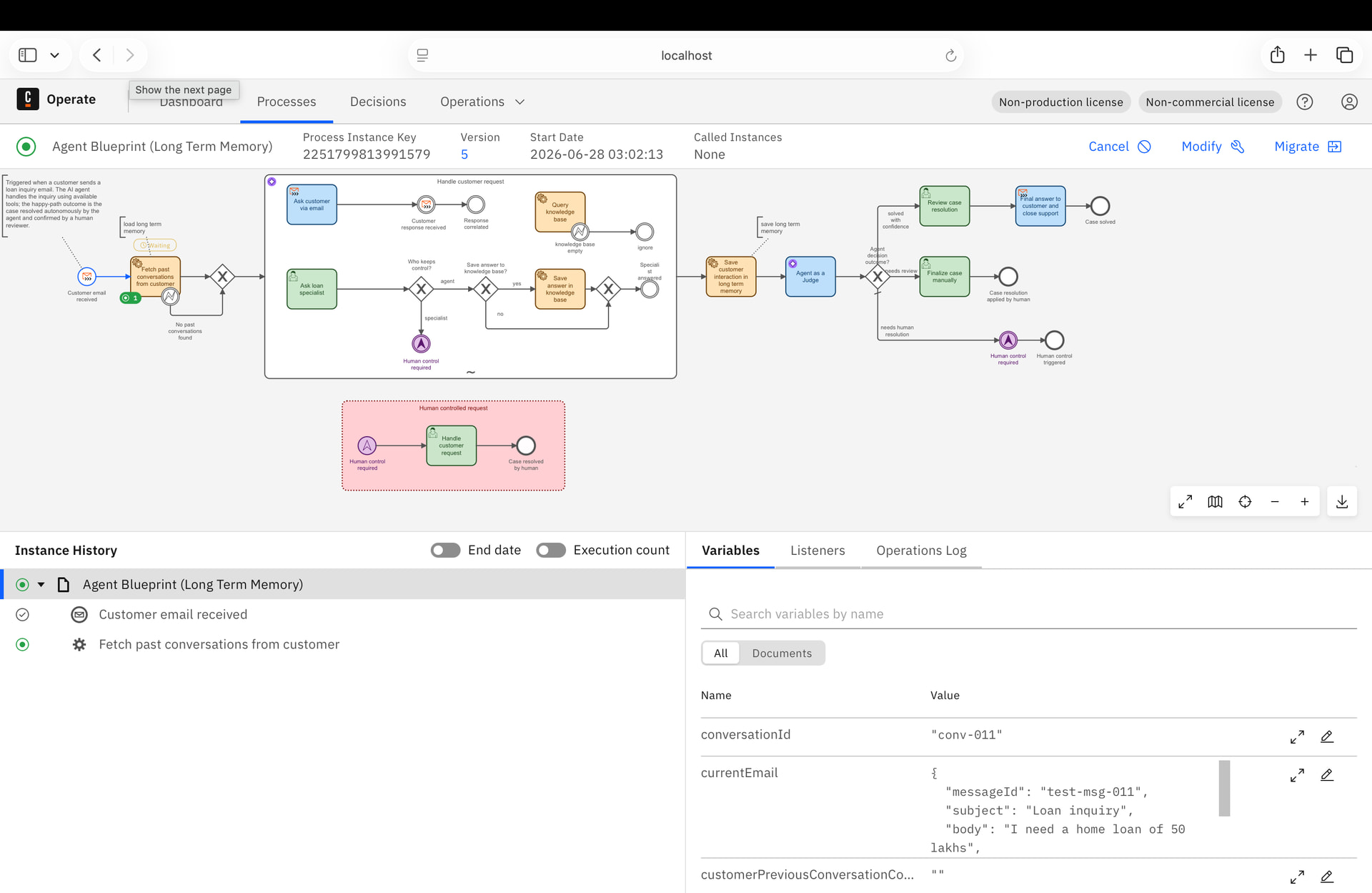
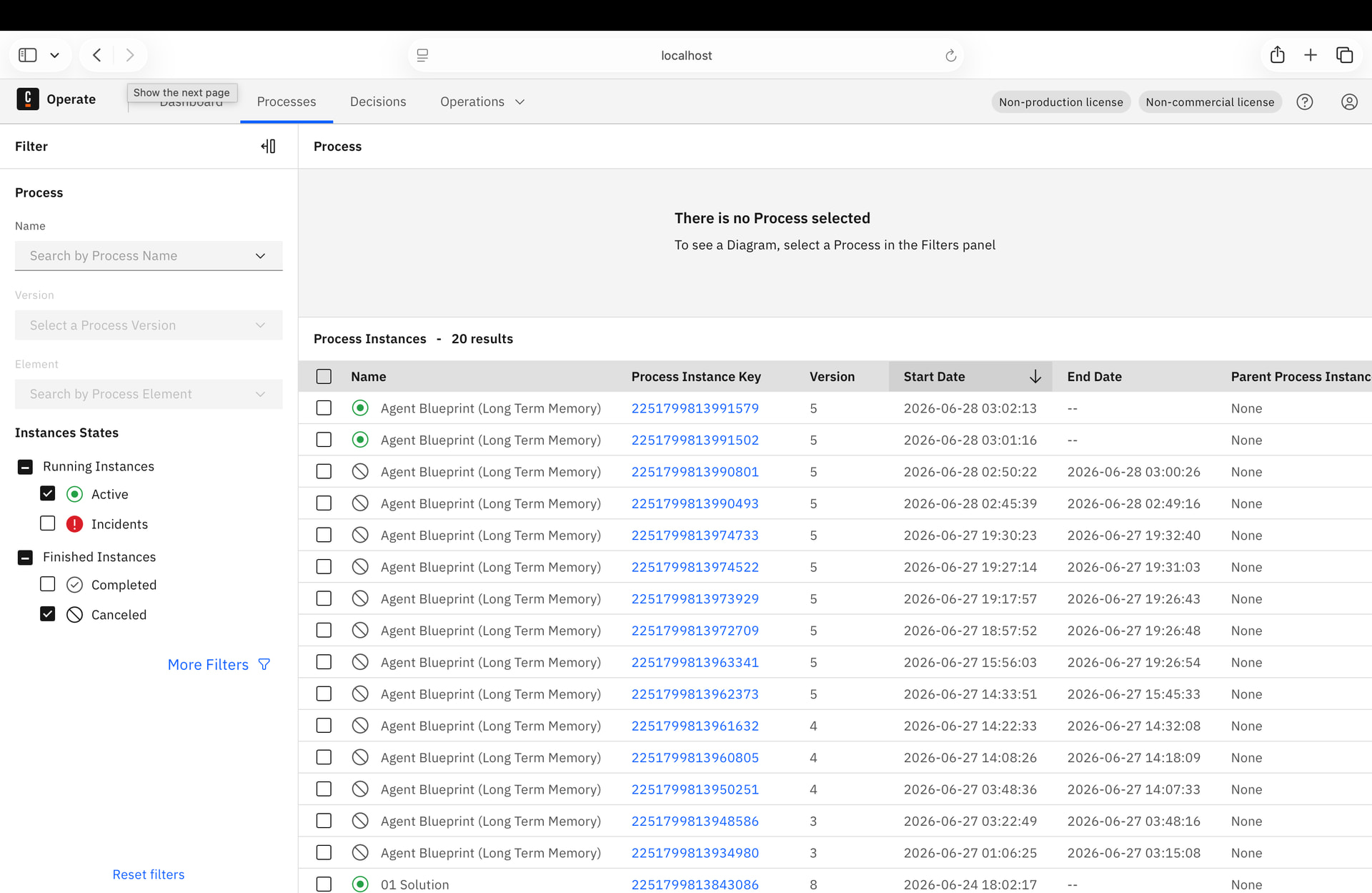
After deploying and running the blueprint BPMN via Web Modeler, process instances became stuck at the embeddings task due to repeated AWS Bedrock 429 (throttling) errors. Zeebe’s StreamProcessor partition repeatedly went UNHEALTHY, causing all connector workers to drop with GOAWAY.
When we attempted to cancel the stuck instances via REST:
POST /v2/process-instances/{key}/cancellation
We received:
json
{
"title": "NOT_FOUND",
"status": 404,
"detail": "Command 'CANCEL' rejected with code 'NOT_FOUND': Expected to cancel a process instance with key '...', but no such process was found"
}
Yet Operate shows these instances as ACTIVE (green). There are 2 such instances. We suspect this is a state divergence between Elasticsearch (Operate) and Zeebe’s internal log, possibly because the partition was unhealthy when the instances were last checkpointed.
Question: Is there a supported way to force-cancel or purge process instances that Operate shows as ACTIVE but Zeebe rejects as NOT_FOUND? Is this a known issue in 8.10 Self-Managed?
Issue 2 — Using Anthropic API key without AWS Bedrock embeddings
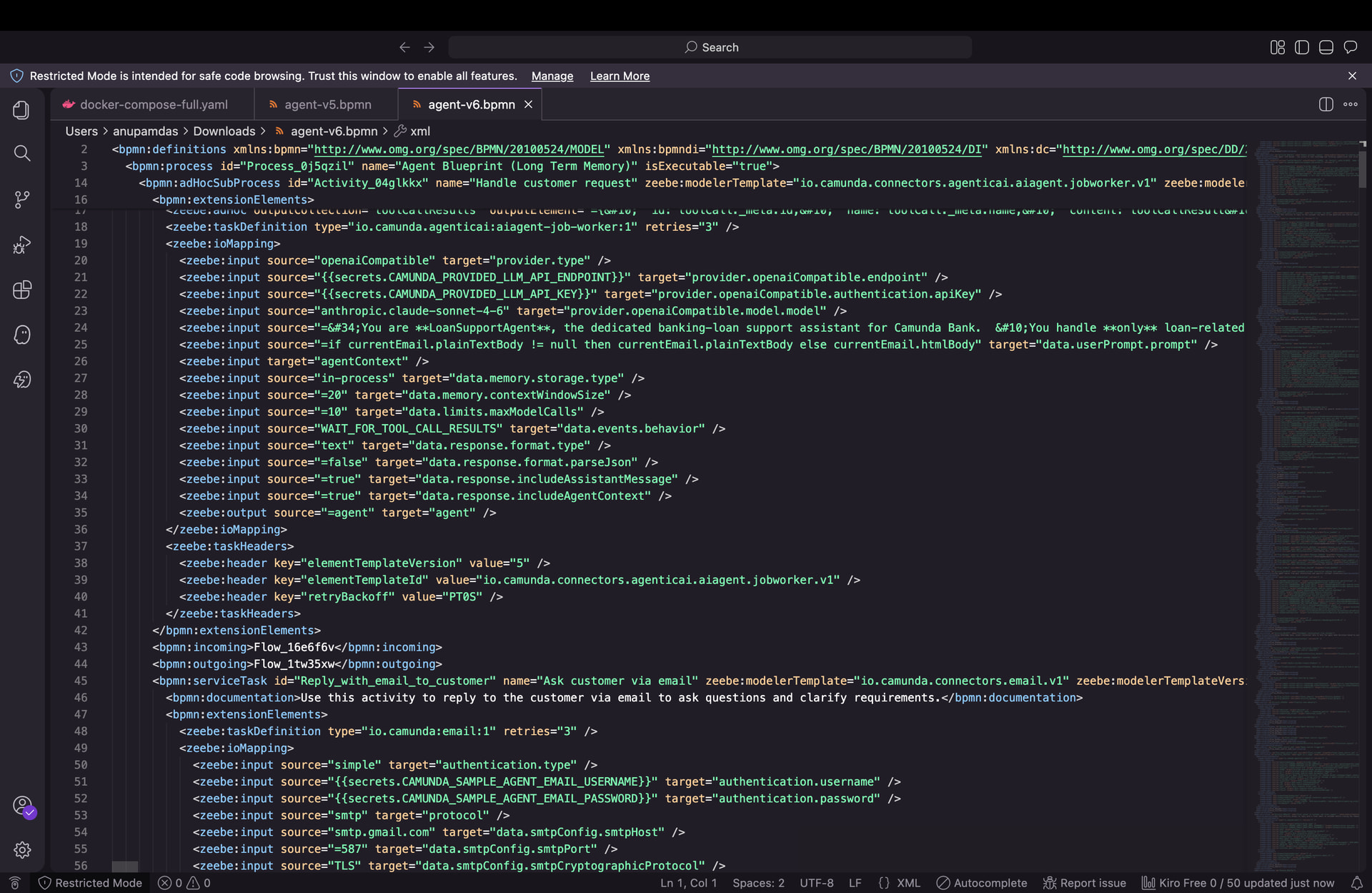
The blueprint’s BPMN uses the embeddings-vector-database connector to fetch past conversations before the AI Agent step. Since we have no Bedrock access, we:
-
Deployed a local OpenSearch instance (
mock-opensearch) as the vector store endpoint -
Set
CONNECTORS_SECRET_CAMUNDAAGENT_AWS_LONGTERM_MEMORY_SERVER=http://mock-opensearch:9200 -
Modified the
errorExpressionon the embeddings task to=bpmnError("index_not_found", "Skip embeddings")to force the error boundary path
However the connector still attempts to call AWS Bedrock Titan Embeddings to generate the query vector before hitting OpenSearch, causing 429s regardless of the OpenSearch endpoint. The errorExpression only fires after Bedrock is called and fails, which still triggers the partition deadlock under repeated retries.
Question: Is there a supported way to configure the embeddings-vector-database connector to skip the embedding generation entirely and take the boundary error path immediately — without making any outbound AWS call? Or is there a mock embedding provider we can inject?
Issue 3 — Bypassing embeddings entirely via BPMN design
We deployed our own modified BPMN (version 3 of the same Process_0j5qzil) where the errorExpression is set to always fire: =bpmnError("index_not_found", "Skip embeddings"). However when a new email arrives, the connector runtime activates the inbound email connector and logs new-email, but no new process instance is created for version 3 — the job never reaches the embeddings task.
We suspect the email inbound connector’s deduplication ID (<default>-Process_0j5qzil-agent-general-email-channel) is anchored to the original Web Modeler deployment and is not re-evaluated when we deploy a new version of the same process ID from outside Web Modeler.
Question: How does the deduplication ID work across BPMN versions for the email inbound connector? If we redeploy the same processDefinitionId with a new version via the REST API (not Web Modeler), will the inbound connector automatically route new instances to the latest version? Is there a way to force this re-binding?
What we have confirmed works:
-
BPMN deploys successfully via
POST /v2/deployments -
Both email inbound connectors activate on startup and show
Health: UP -
The AI Agent connector calls Claude Sonnet correctly when it receives a job
-
CONNECTORS_SECRET_ANTHROPIC_API_KEYis correctly injected
What we are trying to achieve: Run the complete blueprint flow using Anthropic Claude instead of AWS Bedrock, with the long-term memory step either mocked or gracefully skipped, in Camunda 8.10 Self-Managed.
“After restarting Camunda 8.10 self-managed Docker Compose stack, process instances show ACTIVE in Operate but Zeebe returns NOT_FOUND on cancel. How do I cleanly reset Operate’s Elasticsearch index to match Zeebe’s actual state?”
Zeebe and Operate are out of sync due to repeated restarts during active instances.
Any guidance on the above three issues would be greatly appreciated.
Necessary images to understand our scenario ,its having the Application.yaml as well to you to get a glimpse of our app