Hey Thorben,
it has nothing to do with the exclusive flag. In all of my examples i work with non-exclusive tasks because i want to achieve an efficient parallel execution of concurrent paths. Or better: I achieved a efficient parallel execution of concurrent paths with Camunda but i don’t know why.
I will try again to explain what i do not understand.
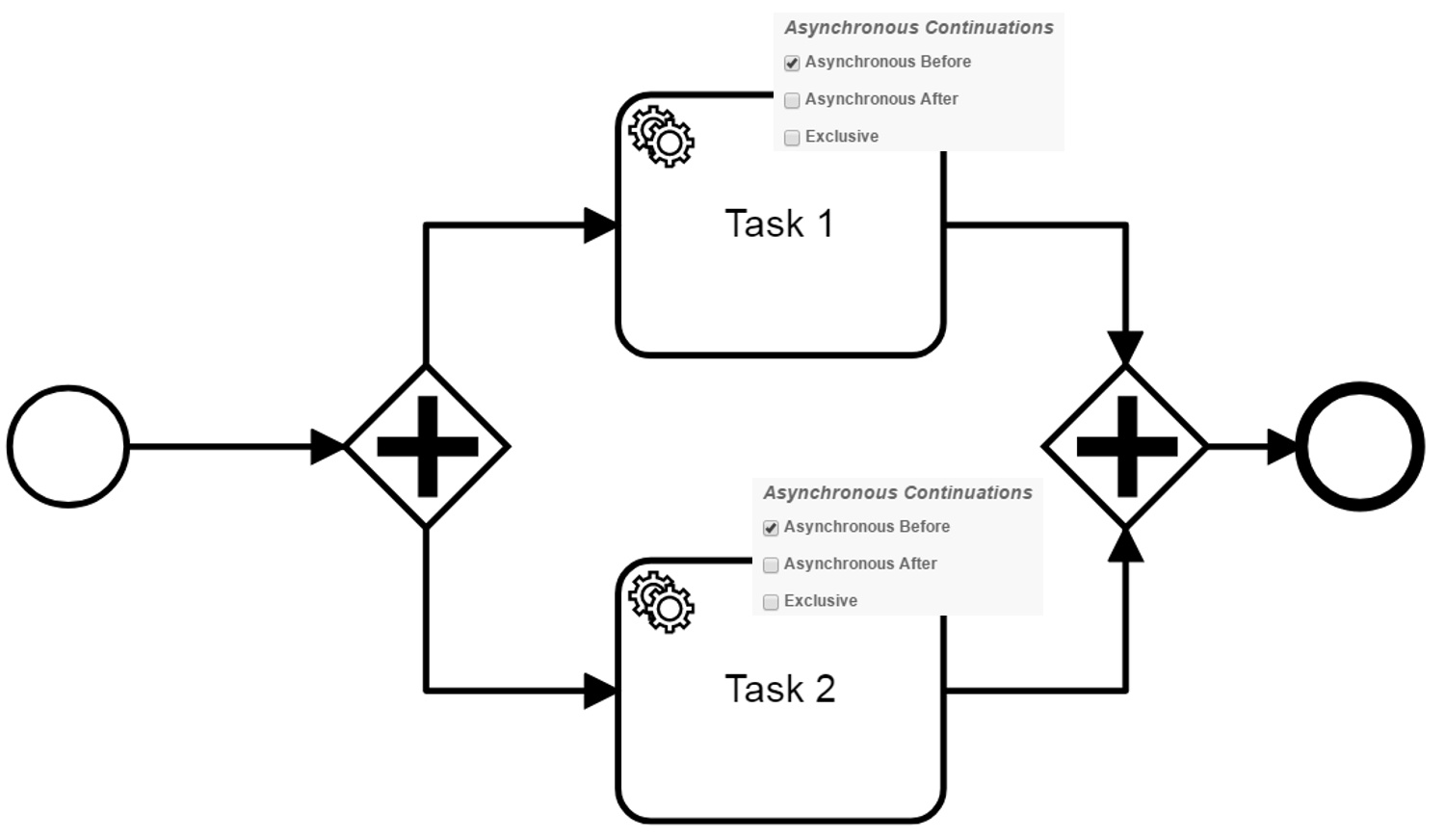
I have this model (model 1):
Executing this model works as desribed above. At the tasks which are asynchronous before, the engine creates jobs. Afterwards, both paths are executed in parallel by different threads of the job executor. One of the paths can be executed successfully. At the end of the execution the transaction increases the rev_ for the parent execution in the database. This leads to an optimistic locking exception when the second path was executed and the transaction wants to commit. As a consequence, the second path will be repeated.
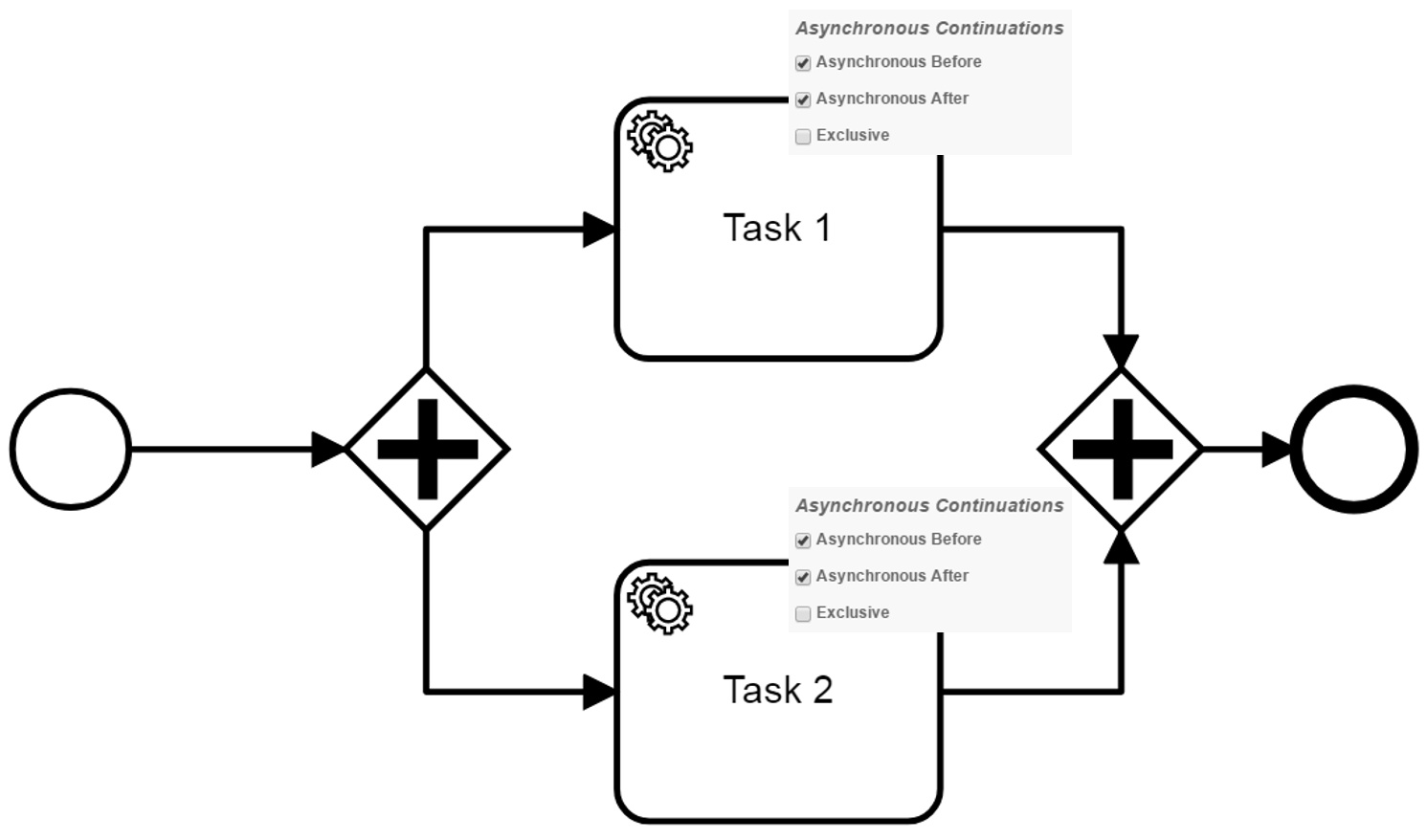
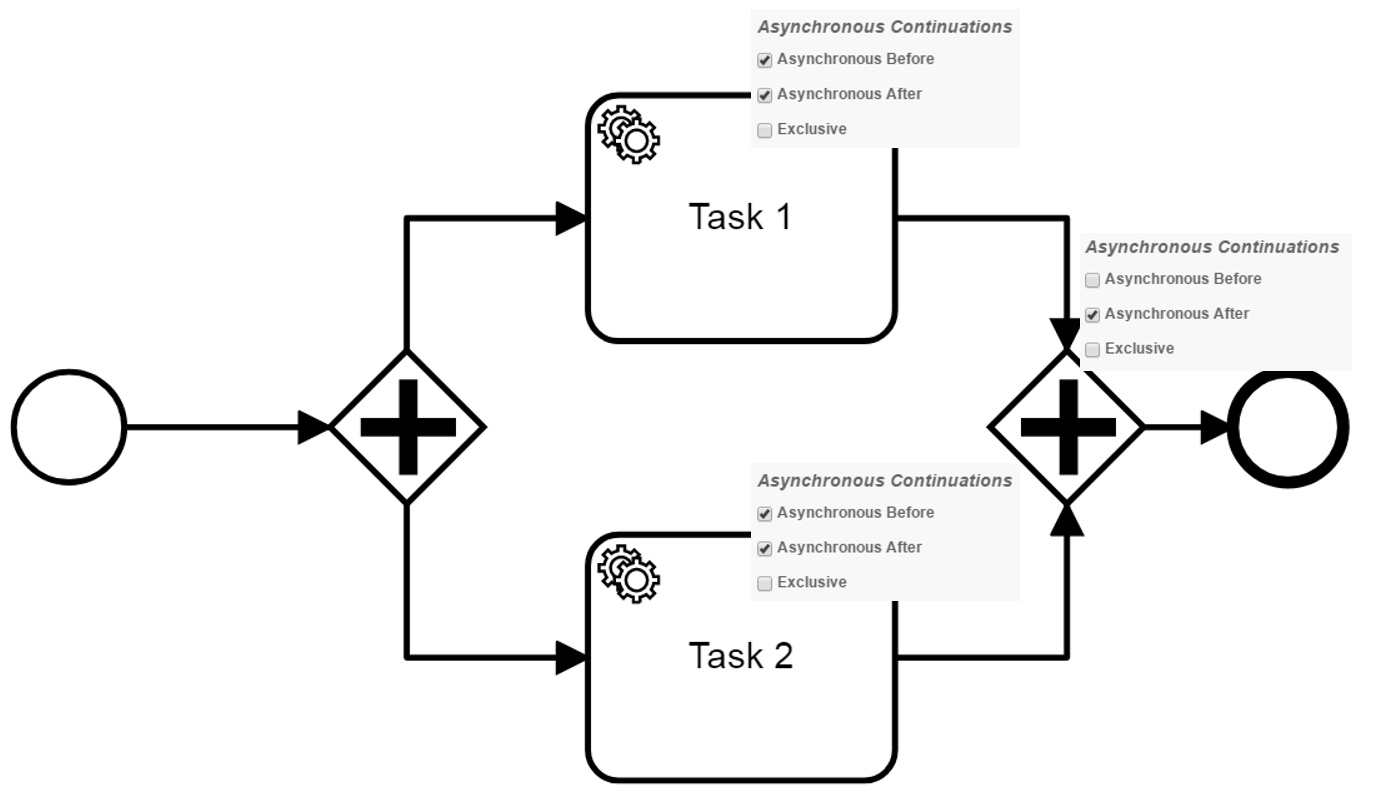
Now i have this model (model 2):
Once again, the engine creates jobs at the tasks which are asynchronous before. Afterwards, both paths are executed in parallel by different threads of the job executor. The asynchronous after on both tasks lead to the creation of new jobs and more important, to transaction boundaries for both parallel transaction. The first execution arriving at the gateway can be finished successfully. At the end of the execution the transaction increases the rev_ for the parent execution in the database.
For now it is very similar and here is the point where i stop understanding. Afterwards, the second path arrives at the gateway and increases the rev_. In my opinion, this should lead to an optimistic locking exception and a repetition of the transaction starting by the asynchronous after of the second path. However, i see that there is no optimistic locking exception anymore.
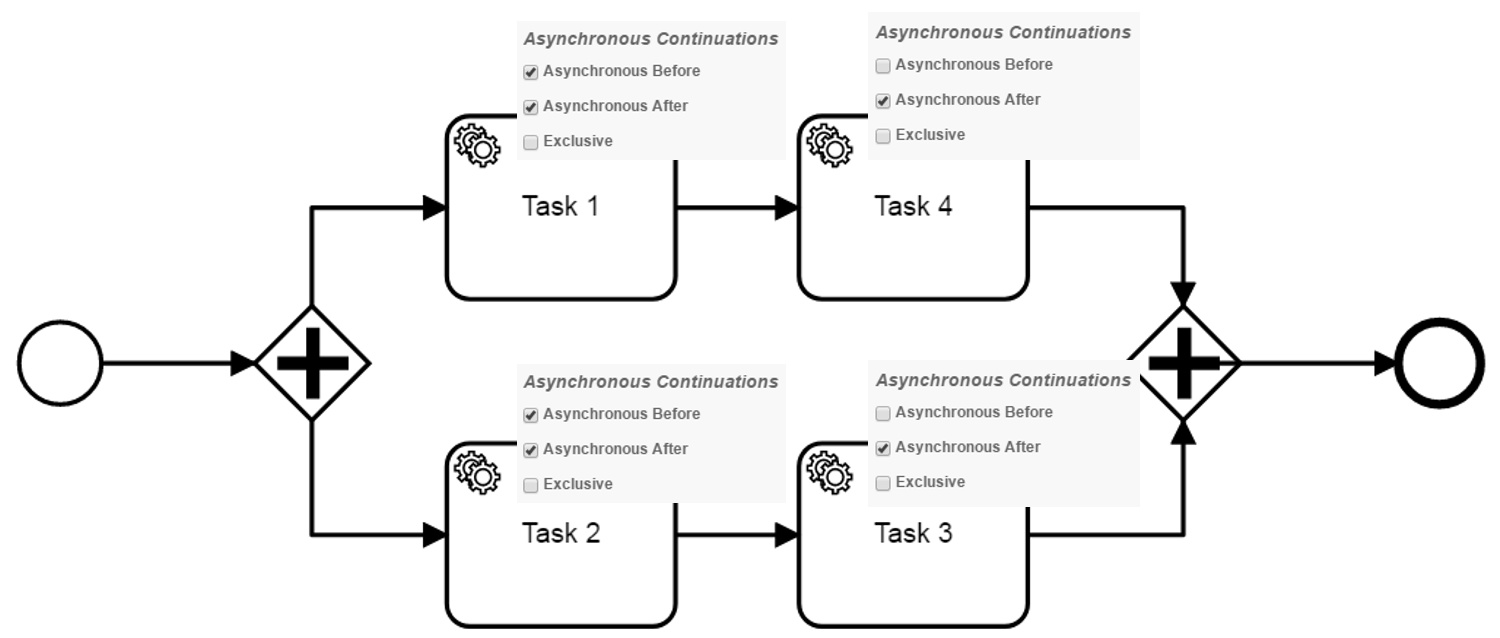
First i thought that asynchronous after makes the transitions non-exclusive again. But then i tried this and observed that Task 3 and Task 4 are still executed in parallel (model 3):
At this point i came to this explanation:
Independent from the asynchronous after, the two parallel transactions still use optimistic locking to synchronize at the gateway. The repetition of the last transaction is only a transition and the join mechanism of the gateway. This repetition is to fast to be a significant problem for an user. Additionally, the repetition does not change the process execution like multiple executions of tasks and the user does not need to pay attention to it anymore. Therefore, the optimistic locking exception still occurs but is not shown on the console anymore.
But then again there has to be some kind of mechanism to detect that between the last transaction boundary and the point of the optimistic locking exception is nothing but a transition and that the execption does not need to show up. You already said that there is nothing like that. And at that point i am just clueless about what is happening when i use the asynchronous after in front of gateways…
I hope i could make my thought understandable.
Thank you for your passion
Jürgen