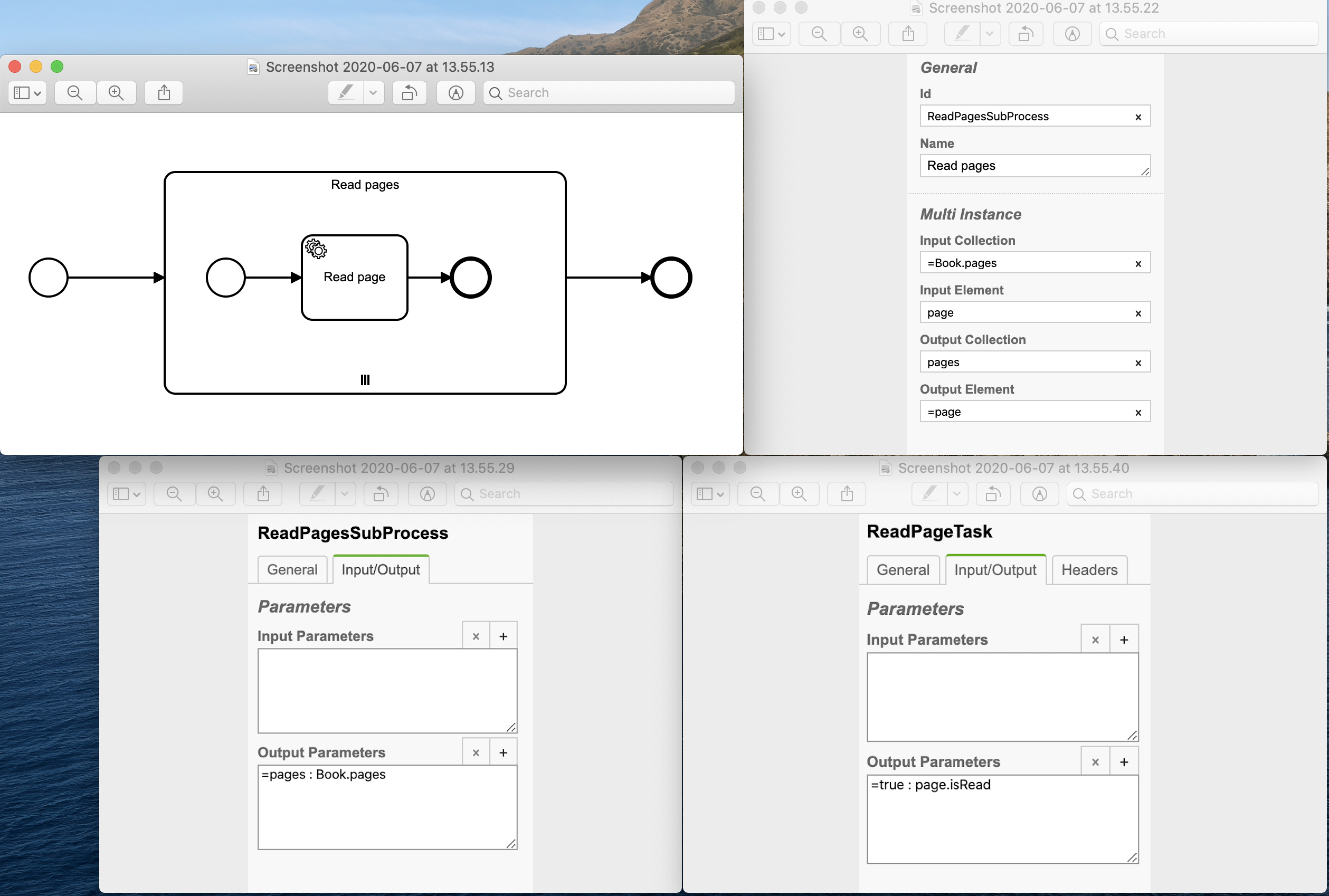
I am referring to this doc, but am a little unclear on interpretation:
https://docs.zeebe.io/bpmn-workflows/multi-instance/multi-instance.html
Let’s say I have a workflow-level variable object:
{
"Book": {
"Title": "My Book",
"Pages": [{
"PageNumber": 1,
"IsRead": false
}, {
"PageNumber": 2,
"IsRead": false
}
]
}
}
My parallel multi-instance would have a single task that will (after some processing) mark each page as read (will set IsRead = true). So I would set the multi-instance Input Collection to:
=Book.Pages
and the Input Element to:
page
so I can access local-scoped page variable. Since I am running a parallel multi-instance, I’d like to avoid race condition on variable update and have my IsRead values for each completed page get updated in the original workflow-level variable object (i.e. I don’t want to create a new variable with the result). When a client completes each page processing, it can update a locally-scoped page variable. So what should I set the Output Collection and the Output Element to - so that a client worker code, upon completing a service task, would update the “page” local variable’s IsRead property to true, and the result would be propagated to the original Book object? Thanks.