we are using Zeebe in production, but we are suffering problems that we cannot reproduce. Randomly one workflow execution gets blocked and the worker taking that jobType is not activated, but after aprox. 300 seconds, it is activated.
Our workers use Java Clients, and we have workers deployed in k8s cluster, but Zeebe is installed outside the cluster, in 3 MVs, one for gateway standalone and Elastic, other with 3 brokers and the last one with other 3 brokers. Our Zeebe cluster configuration is:
cluster size: 6
partitions: 4
replication: 3
We don’t know why is this happening (no cause in logs of gateway or brokers), and we decided last week to move to a new Zeebe Cluster in version 0.26.1, but we are having the same behavior.
We have found this environment variable ZEEBE_BROKER_STEPTIMEOUT, which has 5 minutes as default value, and we don’t know if that is the reason to workers to activate 300 seconds later when the unknown error occurs.
Do you have any ideas about this random behavior?
Any idea is greatly appreciated, as we are receiving doubts about Zeebe.
Thank you in advance.
This could be caused by a worker activating the job, then not completing the job. The broker would then time out the activation, and make it available to another worker.
Could this be the issue? What timeout are the workers specifying when they activate jobs?
Hi @jwulf, we have workers that don’t set requestTimeout (and I understand that by default this time is 20 seconds), and we have a requestTimeout of 6 seconds in some of them. We are always using send().join() when sending commands from the workers.
But we don’t know why we get that random behavior of workflows that are paused in a step (it can be in different steps of the same workflow), and the worker is not activated, but after 300 seconds (and we don’t know why after this exact period), the worker is activated and the worklow completes correctly.
I don’t think it is 20 seconds. The timer sweep for job activation timeouts is every 30 seconds. So anything less than that cannot be guaranteed. See here: https://github.com/zeebe-io/zeebe/issues/5073.
You might find it is five minutes. I’d check the Java client source code.
Hi @jwulf, you are correct, I have reviewed Java Client 0.26.1 source code and the default jobTimeout is five minutes.
But my question is, do you know why we are having that behavior of job launched, but corresponding worker not activated? (We have logs of activation init in workers, and ramdomly, they don’t get activated, as there are no logs) . After those 5 minutes, the worker is activated and the execution of the workflow completes ok.
I think what you are describing is “token enters the task, job is activated 5 minutes later by worker”.
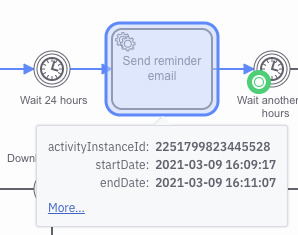
You haven’t described it here, but I am imagining that you are looking in Operate and seeing the task activation startDate and endDate, like this:
Am I correct so far?
If I look at this example from one of my workflows, I am left wondering: is the startDate the token entering this task, or the worker activating the job?
I’m not sure.
But anyway, when I roll my 20-sided Zeebe debugging dice, it says that your worker is not completing the job, and it is timing out and being reactivated.
The worker has a code branch in it that under some combination of circumstances does not throw an unhandled exception, and does not call job.complete(). It’s activating the job, not throwing, and not completing it. The job is then timing out on the broker and being reactivated. The second time round the stars do not align, because it is an edge case. So you do not see it happen twice in a row, and hence a delay of 10 minutes for a job.
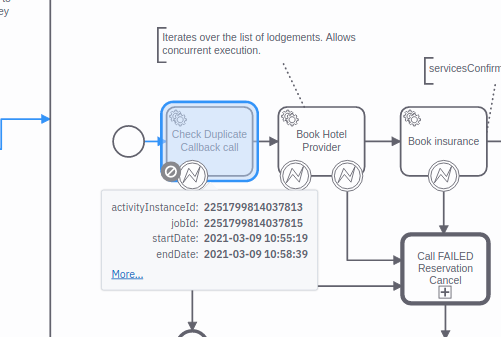
Exactly @jwulf, that is our case, we are seeing that executions from operate, like this example:
In this case, the execution is stopped after 205 seconds as we have this workflow rounded by a timer event of that duration.
We are getting this behavior in different workers of this workflow, and we don’t see in none of them the first activation trace (we are using Java Client workers, with Spring Zeebe Starter, deployed in K8s):
@NewSpan("check-duplicate-callback-worker")
@ZeebeWorker(name = "checkDuplicateCallback", type = WORKER_TYPE)
public void checkDuplicateCallback(final JobClient jobClient, final ActivatedJob job) {
try {
long jobKey = job.getKey();
log.info("INIT {}. JobKey: {}", WORKER_TYPE, jobKey);
And we are not seeing any “INIT” execution in logs.
We have migrated our cluster from Zeebe 0.23.7 to Zeebe 0.26.1, and we get this behavior less frequently, but it still occurs.
If you have any idea it will be greatly appreciated!
If the job is not activating in the worker, then I would suspect the polling of the client.
Intermittent errors are challenging to debug. Trying to get a reliable reproducer is one approach. This exercise forces you to identify the exact set of circumstances under which it happens.
Using open source software, you have to consider the source code as your own source code. You didn’t write the Spring client or the Java client that it wraps, but it is your application code.
So one approach is to reason through the code and look for places where you can instrument it with debugging statements to say things like “I’m polling the gateway for more jobs”, “I got a response back”, etc.
And you need to build a minimum reproducer that does just the things needed to demonstrate the problem. Many times, building this reveals the problem, as you are forced to introduce things one-by-one until you can reproduce.
Given your description of it so far:
It’s intermittent
The broker enters the task
The worker does not report INIT of its handler
The job is re-activated after the duration of the worker request timeout
It’s most probably in one of these places:
Some problem in the broker that does not make the job available for activation (possibly, maybe not likely because not reported by others)
Some problem in the Spring client around polling and activation.
Some problem in the Java client around polling and activation.
I would change the activation timeout in the worker. If this changes the delay (from 300 seconds to the new value of the activation timeout), then this will demonstrate that the gateway has activated the job and streamed it to the worker, but the worker is either not invoking your handler, or not sending the complete message back to the broker gateway. And then I would inspect these two points in my reproducer.
Thanks @marcoplaut, that does look like it could be it. Totally consistent with this behaviour.
@antoniodfr - can you please add a comment to the GitHub issue stating that you are seeing it with the Spring client? That helps with the impact triage and will affect the prioritisation of a fix.
I’ll raise it in the stakeholder input meeting next week, if it hasn’t been fixed before then. It sounds like a timing edge case that isn’t caught in unit tests.
@jwulf what is particularly complicated with that issue is that it’s not always happening and it seems to be (in my case) happening a lot when using a k8s cluster with multiple nodes but is really rare when I run the same test locally on Docker.
If I can help to test a fix, or help to reproduce, do not hesitate to contact me.
Running locally with Docker means a single broker?
In that case it may be a timeout between the gateway and the broker, ie: the gateway gets the job from the broker and says: “ACTIVATED”, but then the requestTimeout to the client times out just then, so the gateway does not forward the job to the client.
This seems to occur when the requestTimeout limit is reached right as a broker streams a job to the gateway for the request.
If you tune it so that the gateway always fills the number of jobs for the request before the request times out (by expanding the requestTimeout or reducing the jobs, or both), then this condition can’t occur.
This might reduce / remove the scenario while we’re waiting on the root cause fix.
By default, there is a timeout of 15s between the Gateway and each broker nodes (partition leader) [See here]. So if you have 3 partitions, then you have a total timeout exposure window for the job activation request of 45s in the cluster at the worst case. So your request timeout for the client should be 45s plus 10s to be safe.
As @marcoplaut and @antoniodfr told us we are under the same scenario with Java Client (Spring), we are experimenting intermittently pauses execution when multiple pods for the same worker are running in the kube cluster. It is being really difficult for us to reproduce the problem.
We are going to apply your workaround reducing maxJobActive property in the client and deploying a workflow in our kube cluster where the workers will run in a single pod instance mode in order to check if the problems disappear
Last Thursday because of the impact of the problem we decided to reduce a single pod instance our workers’ deployments in our kubernetes cluster. The aim of this action was to check if the intermittently pauses execution disappears or has a minor impact on the environment/workflows.
It seems that with this single worker deployment the problem has disappeared from the last Thursday. Maybe the multi instances worker deployment was the root cause of the problem because of some condition race between the different worker instances.