I am currently assessing multiple possible use cases to be handled by the engine.
A concern that I have is about the Zeebe Job Type metadata that is used to
subscribe workers to tasks.
My concern is the following:
Assuming you have multiple services, and you want to enable the possibility to create
different kind of workflows inside those services (basically a service owns a workflow).
You use Zeebe as central component.
I see a strong possibility of having, not by intent, the same zeebe job type, placed in different unrelated
workflows, from different services.
Therefore workers can from one service can handle jobs from the workflow that is not linked with that
service. Expecting maybe some particular variables, and even do some specific handling that only
works for the workflow that is owned by that particular service.
I know the Zeebe purpose is to act as a broker. But this just seems like something tricky. If you work
with multiple people, working in different services, I see that a possible scenario.
So I am curious what can you do to protect from something like this. My thoughts are:
Enforce somehow the uniqueness of the zeebe job type, between different workflows ? Is
something like this possible ?
In the worker code from a service, filter the job metadata to be linked with the process id that
the service owns. But the issue I see here, is cause even if you ignore the other task, from a
different workflow it will still delay the execution of the other workflow. Cause it will take a time
till the ignored task is rescheduled.
Promote a design mindset on all the people involved in the project to take into account this
behavior, but again this still is prone to unwanted effects
Based on the architecture I have in mind for the system, I think the way to have service owned workflows that do not span other services, seems a good approach in my situation.
But I have this concern in mind.
I would appreciate any advice on this, thank you !
The deployment of Zeebe as a service agent, instead of a central cluster, I still don’t think it solves the problem, cause the same issue you could have, by having two workflows in the same service.
I think what I am looking for is a way to enforce that a worker for a particular job type, will for sure handle
a single workflow, without relying on people remembering this aspect.
The current solution I found till now, is to create a custom validator for the BPMN model, that maybe validates the uniqueness of the task type. So maybe this is a start …
For me for this, I didn’t want to have the possibility at all that a worker for a particular type, could handle multiple workflows. Cause if I just filter out the job, cause I am not interested in that workflow, I will affect it, cause I will delay the execution of that second workflow.
But I guess I can do some custom validation, for the job type when the model is deployed, basically to make sure that the type is unique.
We have a similar requirement where we have one generic workflow but different implementations for the jobs depending on who is using the workflow.
I wish there is more flexibility in how workers subscribe for jobs(i.e. along with the job type, if there is a way to subscribe based on attributes of the workflow - such as - give me jobs from the workflows which have “client” attribute set to ‘abc’).
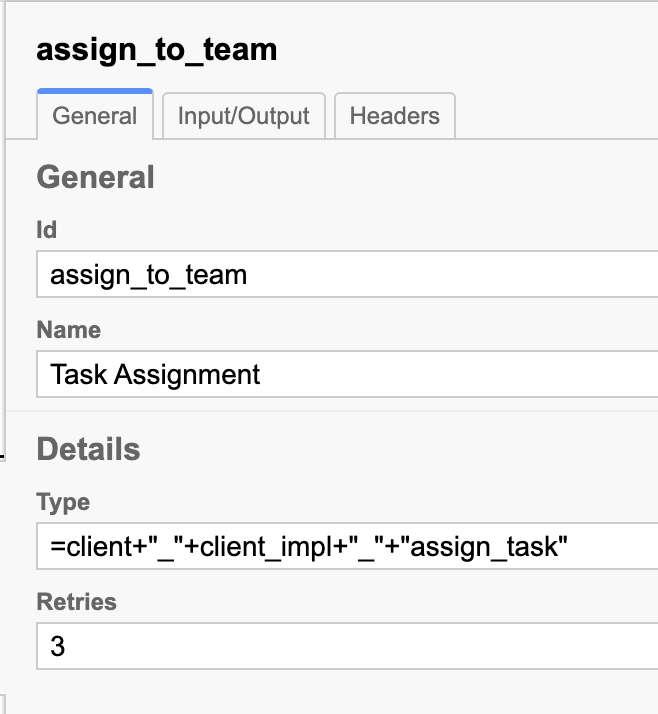
For now, as a workaround, we use expressions for the job type to include attributes of the workflow into job type as below(client/client_impl are attributes & assign_task is the job type):
functionally yes, just that it is bit verbose (& repetitive especially when you have 20+ jobs like ours) and also, because workflow is defined with job distribution upfront (i.e. prefixes in my example) & if i want to change the job worker’s subscription logic(i.e. add another wf_attribute to the criteria), i have to update the workflow.