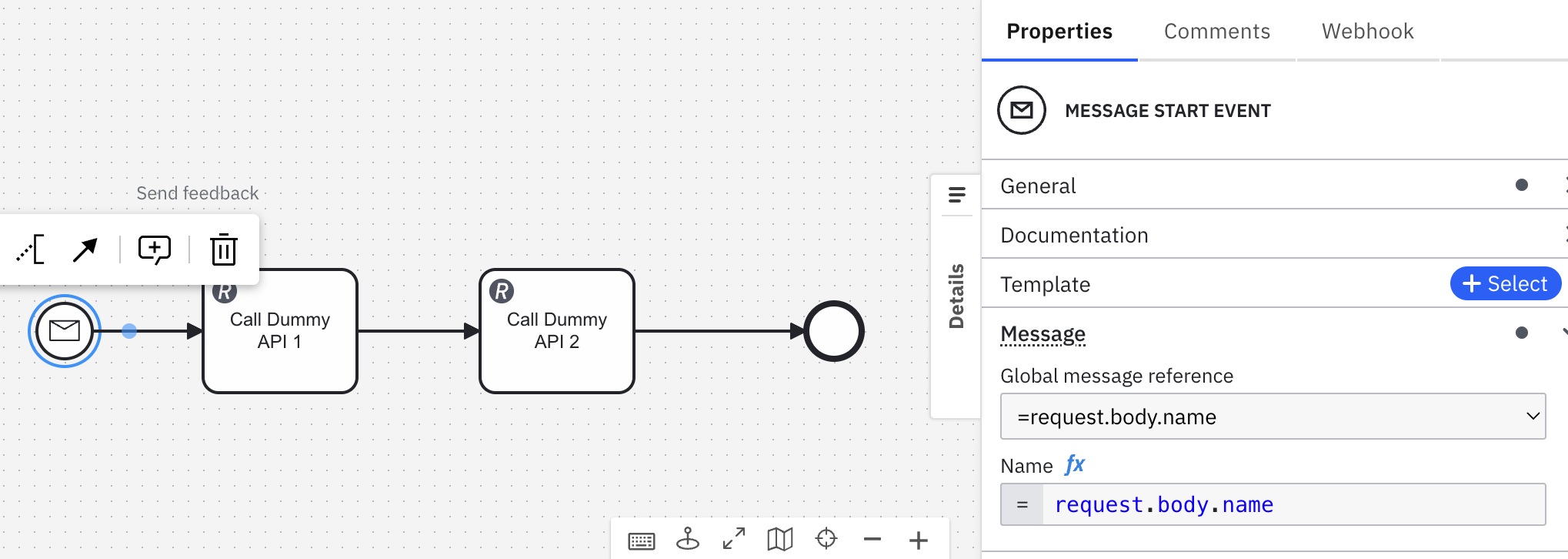
Here, I have defined a starting event that will be triggered with an API call. The dummy API 2 call is failed and I want to trigger the same instance of it so that it will be started from the place where it failed.
How to do that? Do we have to pass a correlation ID or something to trigger it again?
or is there a way user can set the process instance ID and save it in their side and re-trigger it whenever needed? How to achieve this kind of scenario?
or once the BPM process is started, can we send the response to the caller with the process instance ID? If so how to do it?
@nathan.loding Could you help with this?
@brian.kodikara - this is a community support forum, not an official support channel. Please do not tag users that have not participated in the topic already. If you need priority support, I can get you in touch with our enterprise sales team.
Your questions are answered in the documentation:
If you have tried something and it’s not working as expected, share that; otherwise I recommend experimenting and trying something before asking on the forum.
@nathan.loding
Thanks for the response. I did want to get a solution but couldn’t find any doc. Sorry for the inconvenience caused.
BTW I didn’t get the answer to the question yet. I want to re-trigger the same workflow instance via a webhook call. Provided documents doesn’t present answer to that.
@brian.kodikara - I am not quite sure what you’re asking. You can start a new process instance. You can also use the Zeebe API to move the token to a certain task in the new instance (though this isn’t recommended).
You asked to restart the process instance “so that it will be started from the place where it failed” - this is the purpose of retries in the Connectors, and the guidance for handling failures explains how to model failure and incident handling in your processes. Specifically, the section about “Handling errors on the process level”: you could model an error event that loops back to a previous task, for instance. (This blog post has a great section on modeling a retry.)
To be more explicit, the best practice isn’t to fail the current process and restart it; the best way is to model the exception/error path in your model.
@nathan.loding Thanks for the response.
I have explained the requirement in more details in this question. In our use case there is no explicit way to handle errors. we can add retries and other than that it will fail if the retries fail. https://forum.camunda.io/t/special-requirement-for-triggering-unfinished-failed-instances/52361
What we want is,
- Trigger a workflow
- Get an acknowledgment if it is finished.
- Find the unfinished workflows
- Re-trigger the same workflow instances that were failed/unfinished. We don’t want to start a new one because it will be costly to run the same tasks again. We though that there would be a way to re-trigger the same workflow instance that was failed.
One of the middle tasks can fail and we can add retries. But still it can fail. So we want to re-trigger the same instance again (Not manually). As an example, due to a github outage one of the tasks in the middle can fail. On our side, we check for triggered workflows that were not finished. So we will trigger unfinished/failed ones. However I am not sure how to re-trigger unfinished/failed workflow instances in Camunda using some API call.
Lots of workflow instances will triggered by us. So we want to identify what are the finished ones and what are not. So we need a unique id/instance id. Atleast if we can return the instance id when the workflow instance started. We can call the camunda REST API to get the list of instances and check whether there are any incidents and re-trigger failed ones. Camunda holds the state/env even if there is a failure. So it is possible to start from the failure again. Let’s say after 1 hour, github outage could be solved and we can restart the workflow from that task onwards without restarting from the beginning.
That’s what we want right now. If you could give some insight, it would be really beneficial for us to go with Camunda as a solution to our requirement.
I am eagerly waiting for a clarification. Sorry if I do not fully understand the concepts in Camunda yet. I am still evaluating Camunda for our use case and understanding its concepts.
Thank you!
@nathan.loding
I can see that in the “Operator”, we can re-trigger the incident (failed task) and the instance will continue until it is finished. I want to do it from outside (e.g.: some API call) without doing it manually.
Since this is possible manually via Operator, why isn’t there a way to do it via an API call?
If it can be done in an API call, we need some ID to trigger the same workflow instance.
@brian.kodikara - of course any task in any process can fail. The recommendation, again, is to explicitly model your failure paths so that the process can handle it. That is the best and most supported way to do this.
When a task fails, it will generate an incident. If you resolve the incident, the process will start retrying that task again per its definition. You aren’t finding the API call you expect because there isn’t one: instead you need to be looking at the ResolveIncident API call and the related Operate calls. This is what Operate is doing internally. As mentioned before, it is also possible to use the ModifyProcessInstance API call to move a process instance to a specific task, but this is considered an anti-pattern, is not recommended becaue it can be fragile if not used carefully, and should generally be used as a “last resort.”
(A quick vocabulary clarification: correlation ID’s are a unique value that matches an inbound message to a running process. You can use correlation IDs to send messages to a running process, but they aren’t related to incidents or starting processes.)
Process orchestration is a different mental model than traditional application processes, and requires a slight shift in how you think about them. A process shouldn’t really be considered disposable in a way that you just fail it and start a new process from the same task. Instead you fix what’s wrong with the running process and let it continue. This is also why modeling the failure and recovery paths is a best practice, as well as considering idempotency for each task, allowing repetition (in the case of a failure) without causing issues with your data/results.
(I see that you asked this question again in a duplicate thread and got the same response as here from a community member. Please don’t open multiple topics on the same question so that forum members aren’t duplicating efforts!)