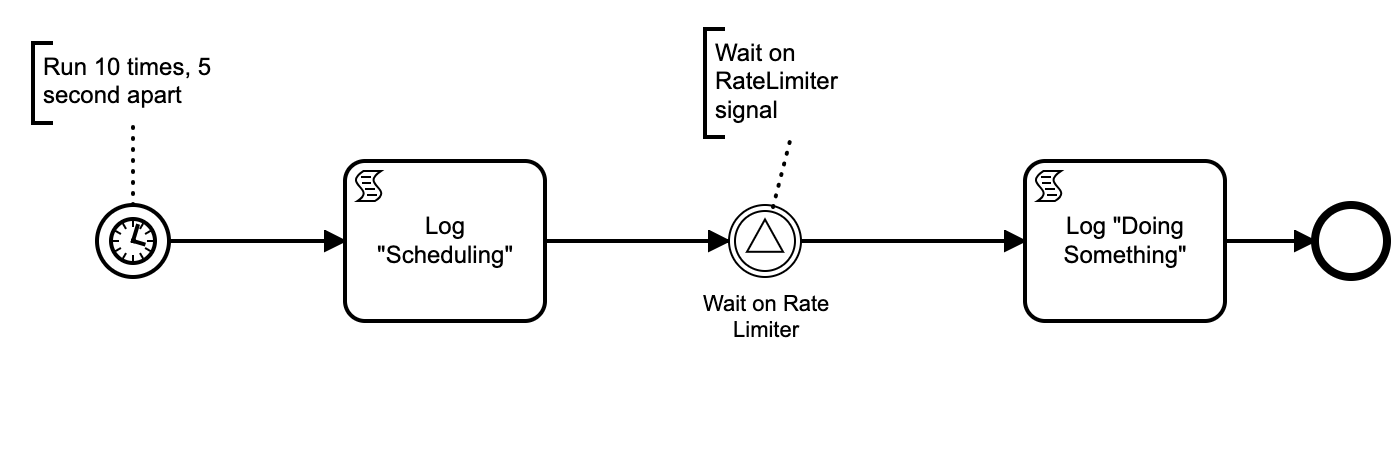
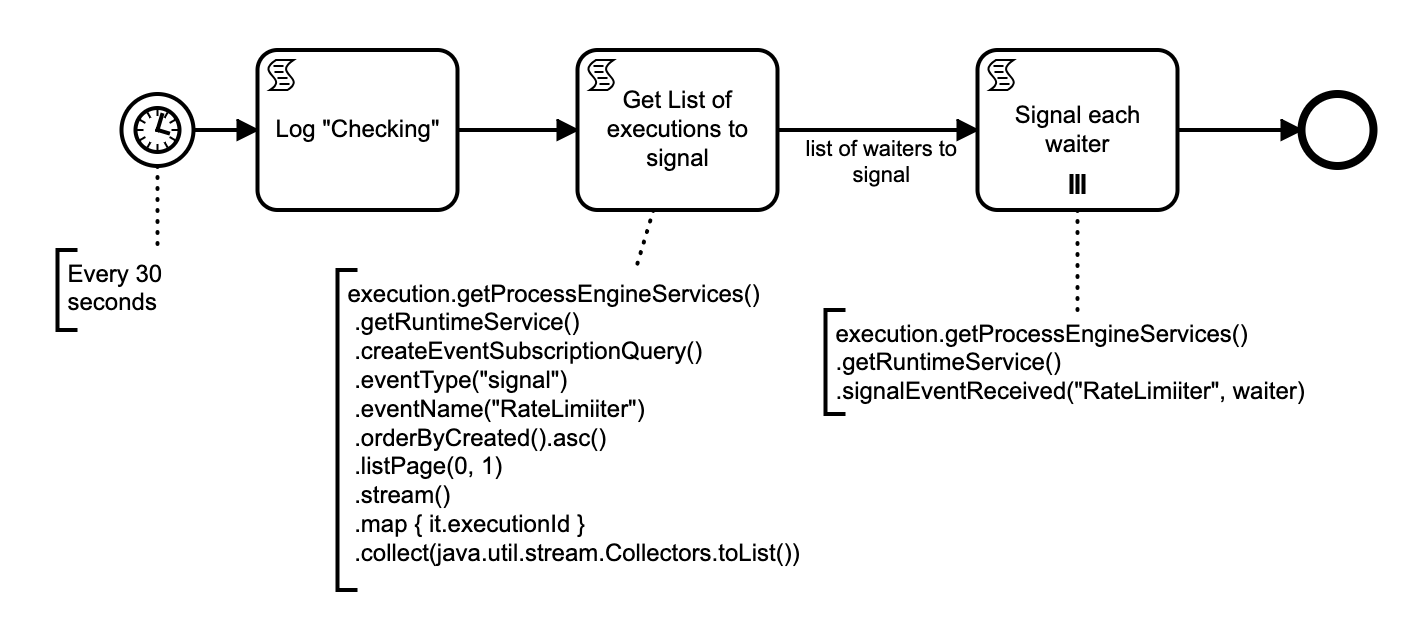
I have a task (which is calling out to an API to get information) that I want to rate limit how often that task can be executed. The API in question will end up blocking you if you slam it with a bunch of requests. So even though I may have umpteen processes whose next step is to make this call I only want to say have the call made once every 30 seconds.
For the record I am very aware of the thread on limiting the number of concurrent executions of an activity, but that is a slightly different problem as it doesn’t care how often the task is executed, just how many parallel executions there are. The solutions presented in that thread also did some handwaving on parts of it so was not clear how to implement it. I also worry that they may have had race conditions.
I have a test solution shown below that does actually work. It simulates 10 processes needing to “Do Something” Every 30 seconds it sees if anyone is waiting on the signal and if so signals the oldest one (can be tweaked to do more than one) to proceed.
What I don’t like about this is that the first request when idle may have to wait up to 30 seconds to proceed. Also once there are no pending processes the periodic checker still continues to run every 30 seconds and does not go idle.
Looking for ideas on how to better implement this that is reliable, does not tax the system when idle and does not introduce unnecessary delay.
Hi Dale,
If I understand your requirement correctly, you seem to want to limit calls to a service to no more than 1 per 30seconds (I can generalise to n per 30s later).
You could still use the semaphore pattern as per the rate limiting thread you reference. In addition, this pattern will get around the undesirable behaviour of the polling behaviour you identify in your solution, eg unnecessarily waiting 30s…
You can use the semaphore pattern to limit the number of concurrent requests to 1 or n. To add the requirement to limit per unit time, you could add a dwell step to not release the semaphore for 30s. You could implement this in a parallel branch of your calling process flow such that the main branch can continue on without having to dwell for 30s.
You talk of race conditions in the semaphore solution, they kinda exist, however their behaviour is stable due to theway the engine works or the intrinsic nature of a semaphore. However, as it is, there is a risk of starvation. Your solution looks like it prevents this by selecting the oldest instance to proceed. You could add this behaviour to the sempahore solution by using priority ordering in the job executor configuration.
Other considerations include network or cluster effects. Do you deploy to a cluster? If so, you need a network singleton. This can be achieved using the database as a semaphore…
Theres a lot of detail I could go into, so reply or message me if you want to do a deeper dive on a particular aspect…
regards
Rob
I somehow missed that you actually posted the BPMN file, so I will look into it further. I didn’t really look at your solution thoroughly and my comments were primarily based on the suggestions by @StephenOTT.
You characterized the problem correctly I only want n executions per some unit of time. The selection of the oldest instance comes from the fact that in the real flow the “Do Something” may fail and that loops back to the wait state. I don’t want to risk retrying the failed one over again immediately instead of trying other ones, so the ordering means the failed ones go to the back of the queue.
I would write a direct sql query against the db to do the time window query. This way you don’t need to get back all of the activity objects. You can access the data source of the db by doing execution.getProcessEngineConfiguration().getDataSource() (or something like that).
Then run your custom commands to get the needed info to make a judgement.
I would also setup a mini plugin that established a concurrent hash map so you can cache the result so you don’t need to hit the DB every time.
After that it’s whatever calculation logic you want to use.
Ok, that really confused me, are you sure you replied to the correct thread?
If you are executing N activities within a time window then you need to keep track of the number of executions within that time window. (The sql), and if you have very high throughout, then would want to cache that request (the map).
If you problem is how to design the Bpmn, my thoughts were you had two pattern options: you use BPMN errors to basically do looping. The execution of the activity starts and checks if you have exceeded count and if yes you set a timer for after the time window expires. Second option was using messages/signals: where when a too many executions you could use a Bpmn error to go to a message event and a event that points back to the task. You can then have a external thread/query running that checks for these paused executions, when found it can send messages to try again when the window and execution count allows it.
Now that’s at the Bpmn level. If these tasks are all over in different BPMNs, then I would prob look at building a extension to the job executor. Similar to how the executor can change priorities for things like timers vs messages, etc, you could setup a executor config that understood the job types and only executed N amount per time window. (Caveat would be your tasks would need to be marked async)
(Unless I completely miss read the goal; always possible  )
)
Edit: if I go back to your original “I don’t like” comment: to solve that you can setup a shared value someone in the system (a static property in a class) that you can update when you check scheduling. When your every 5 second process runs, it checks that shared value.
Here is a example of a simple plugin that sets up a shared “space” for processes to save common data to.