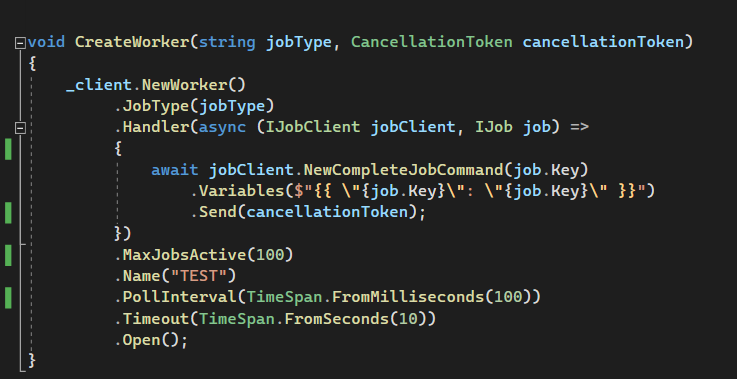
Questions to that:
Are you running on the same machine? Is your setup related to your production setup? If not I would suggest to first setup it close to how it would look like in production otherwise your benchmarks are useless.
In order to improve performance you can always increase resources (like CPU and ram), add more nodes, and increase the partition count to improve parallelism. Furthermore, it makes sense to use a fast disk (like an SSD), since Zeebe is really IO-intense.
Are you using a standalone gateway? An embedded gateway will steal the broker’s resources on high load.
How many workers are you running?
What are your current load and the expected load in production? Do you test with the expected payload? There are many factors/parameters which can influence performance and you should consider all to be close to the production scenario.
In order to improve performance you can always increase resources (like CPU and ram), add more nodes, and increase the partition count to improve parallelism.
64 gb ram and i7-11800h cpu (8 core)
Furthermore, it makes sense to use a fast disk (like an SSD), since Zeebe is really IO-intense.
We are using m2-SSD
Are you using a standalone gateway? An embedded gateway will steal the broker’s resources on high load.
No, it is embedded gateway
How many workers are you running?
Only for this test, 10 worker but they do nothing (only complete method)
What are your current load and the expected load in production? Do you test with the expected payload? There are many factors/parameters which can influence performance and you should consider all to be close to the production scenario.
Current there is only 1 empty instance with 10 flow-node performance. In production there will be maybe thousands. And flow instances will call api calls.
@hmeniz - did you upgrade your setup to deploy on multiple nodes, k8s along with using a standalone gateway?
I am also benchmarking zeebe to figure out the right cluster configuration for our needs. Wondering if we could learn from each other