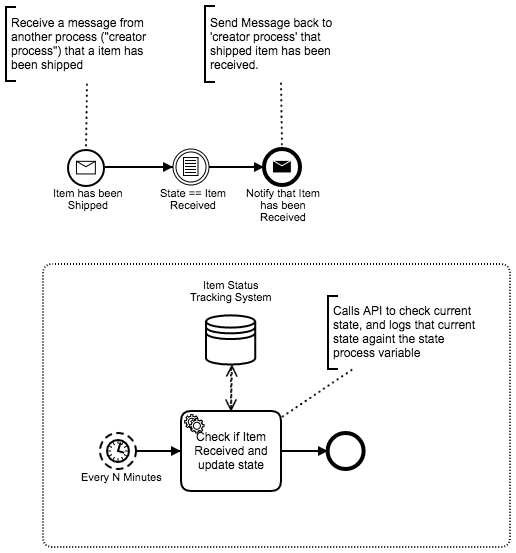
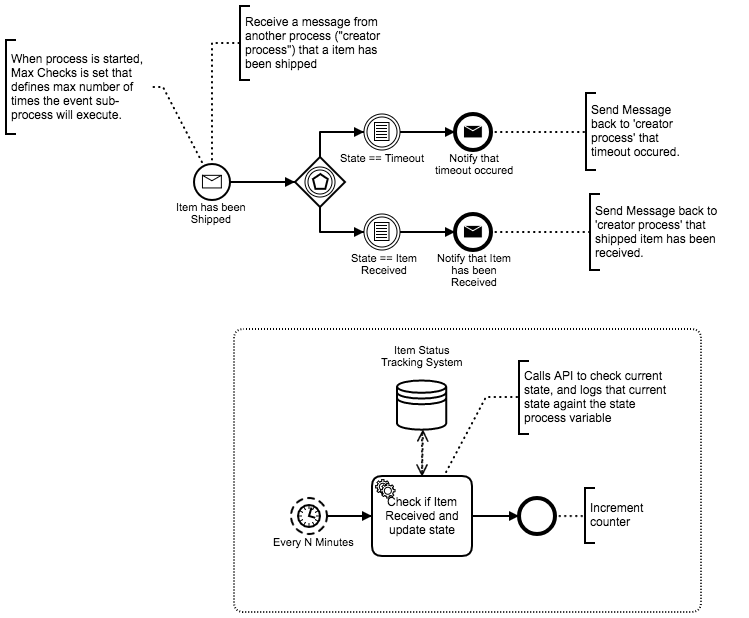
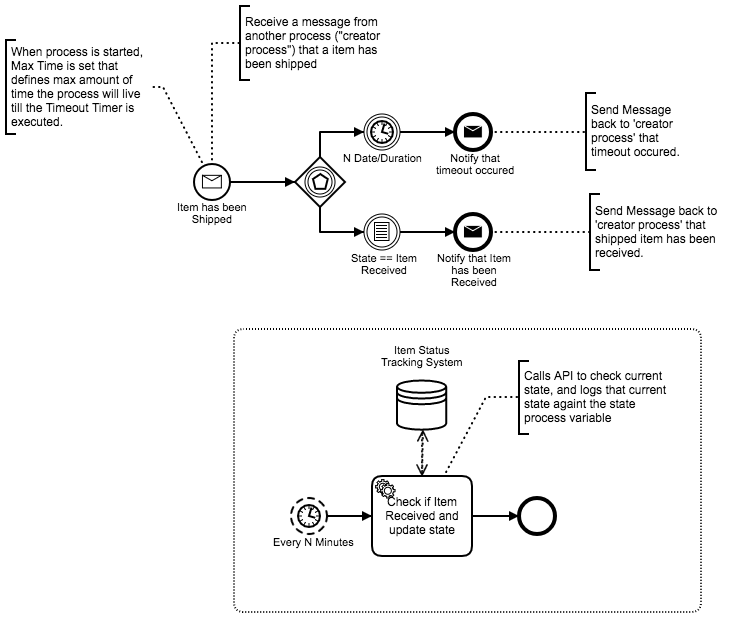
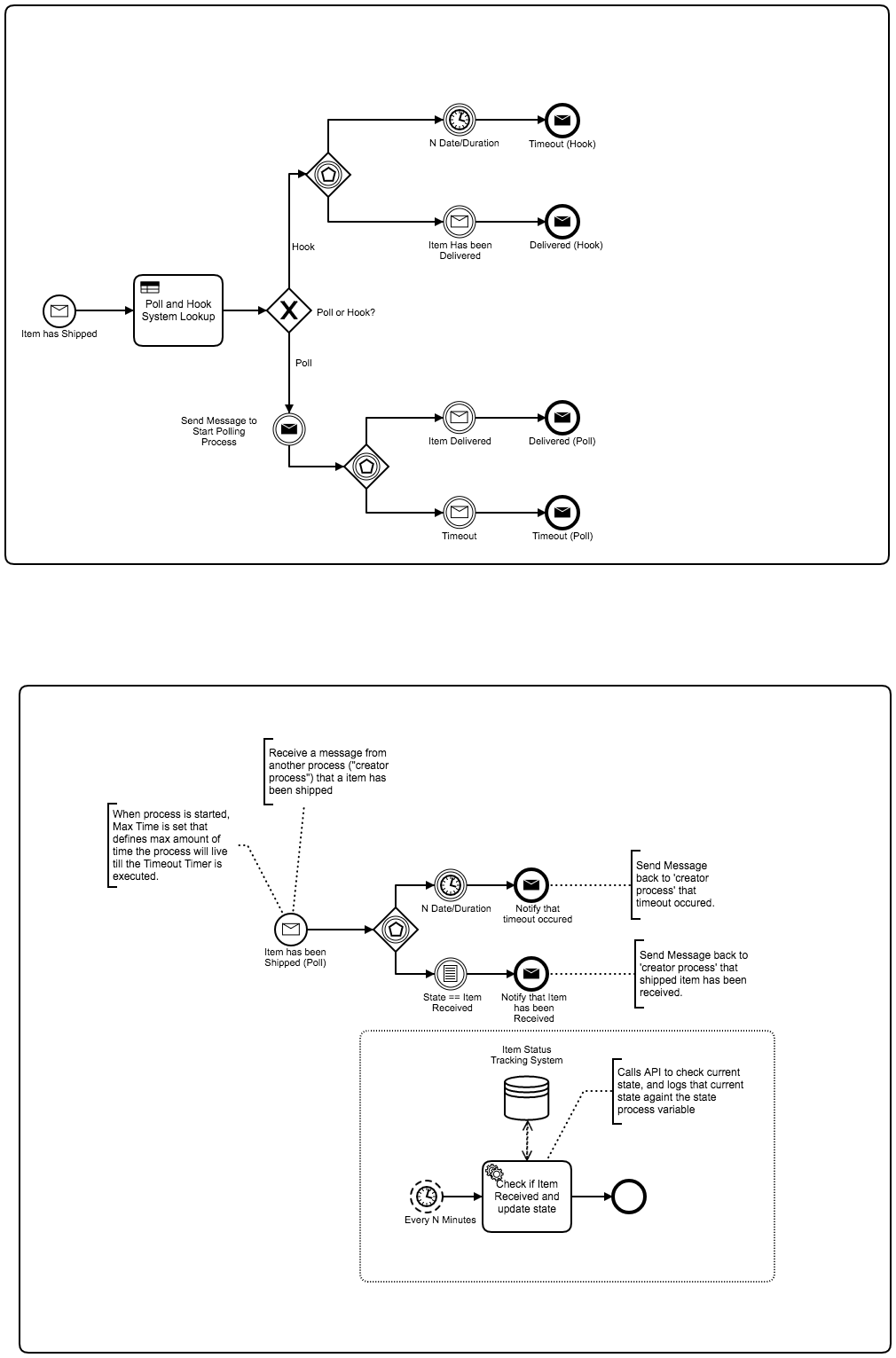
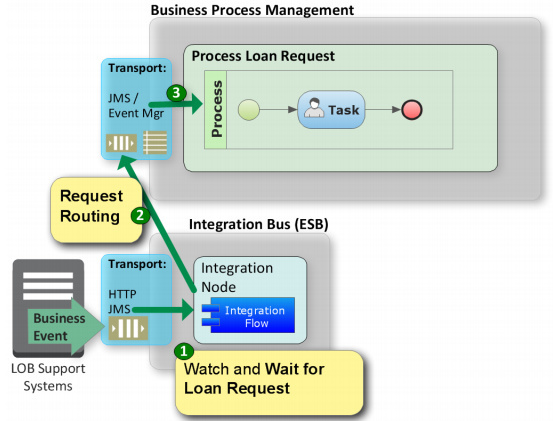
Thanks for sharing these models - discussing these sorts of patterns adds considerable value to the forum. Less technology and more process!
I hope you don’t mind me adding to this topic.
Couple of points -
Why not model the collaboration?
Since we’re looking at, in my opinion, process collaboration… why not model it that way? And, with regards to polling, I’ve run into a few issues with this pattern inside a process instance. This has more to do with implementing the concept of a polling service inside, or encapsulated within, a process model.
Process type, instances, and life-cycle
We need to take the current model and add… (before refactoring with collaboration in mind) yet another perspective. This new perspective takes into account process instance life-cycles.
When viewing the process model as a type and the in-flight process instance as an object representing an instantiated model definition… well, there’s some additional behavior. Empirically, we end up with active timers emitting events within zero-or-more (0…*) process instances (objects). And, in acknowledging the relationship between process-instances and their version type-definitions (the SDLC side of BPM), we correlate the timer-event to process instance per its type (versioned) definition. This is where things get interesting.
Given we have a timers now living within the process instance (referring to ‘polling’), we have a fixed relationship between type (model) and instance. We can’t change the type, with regards to the polling model, without requiring a migration to the new definition! Workaround is to decouple event emitters (focus is polling model) from the process itself. In-other-words, we don’t mix event-generation into our process-type definition. Though we continue logically modeling the embedded timer, as we work towards the executable version we cut over to a more formal pattern for event management.
Referring back to the process life-cycle view, imagine trying to debug your process while a bunch of in-flight process timers are emitting and kicking off in-flight (process instance or object) behaviors… It’s madness. The solution is to migrate the timer execution requirements to something capable of direct management and independent life-cycle.
Cutting this narrative short - my workaround was to introduce an independent timer sub-system. The logical BPMN model remains, because that best expressed our intent. But, the timer implementation, as its own sub-system, provided both direct control (platform-specific configuration) and direct management (i.e. JMX).